
OpenID Connect rozwiązuje problem, który w wielu aplikacjach wraca bez końca: jak bezpiecznie potwierdzić tożsamość użytkownika i nie budować własnego, kruchego systemu logowania. W skrócie: oidc porządkuje logowanie na bazie OAuth 2.0, ale dorzuca warstwę identyfikacji, której sam OAuth nie daje. Poniżej pokazuję, jak to podłączyć w praktyce, co przygotować przed startem, gdzie najczęściej pojawiają się błędy i jak uniknąć integracji, która działa tylko na papierze.
Najważniejsze rzeczy do zapamiętania przed integracją
- OpenID Connect służy do logowania i identyfikacji użytkownika, a nie do zwykłego dostępu do API.
- Najbezpieczniejszy punkt startu to Authorization Code Flow z PKCE.
- Przed wdrożeniem potrzebujesz discovery document, `client_id`, poprawnych redirect URI i walidacji podpisu tokenu.
- W aplikacji webowej lepiej utrzymywać sesję po stronie backendu niż trzymać tokeny w przeglądarce.
- Kluczowe są `state`, `nonce`, `iss`, `aud`, `exp` i rotacja kluczy publikowanych przez dostawcę tożsamości.
Czym jest OpenID Connect i kiedy ma sens
Najkrócej: OIDC dodaje do OAuth 2.0 informację o tym, kim jest użytkownik. OAuth odpowiada na pytanie „czy aplikacja może dostać dostęp?”, a OpenID Connect na pytanie „kto się zalogował?”. To różnica, która w praktyce decyduje o całej architekturze integracji.
Jeśli budujesz logowanie w panelu administracyjnym, aplikacji SaaS albo portalu z kontem użytkownika, właśnie tu zwykle pada właściwy wybór. Nie musisz tworzyć własnych haseł, resetów, polityk sesji i odzyskiwania konta od zera. Zamiast tego korzystasz z dostawcy tożsamości, który uwierzytelnia użytkownika, a Twoja aplikacja dostaje standardowy zestaw informacji o sesji i identyfikatorze.
| Obszar | OAuth 2.0 | OpenID Connect |
|---|---|---|
| Główny cel | Autoryzacja dostępu do zasobu | Uwierzytelnienie i identyfikacja użytkownika |
| Najważniejszy rezultat | Access token | ID token, często razem z access tokenem |
| Co aplikacja może ustalić | Że ma prawo działać w imieniu użytkownika | Kim jest użytkownik i czy logowanie było poprawne |
| Typowe zastosowanie | Integracja z API | Logowanie, SSO, konto użytkownika |
Ja patrzę na to tak: jeśli w projekcie chodzi o sam dostęp do zasobu, zostajemy przy OAuth. Jeśli trzeba „podłączyć logowanie”, wchodzimy w OIDC. I właśnie dlatego następny krok to przygotowanie kilku parametrów po obu stronach, zanim zaczniesz klikać w konsoli dostawcy.
Co przygotować przed podłączeniem
Najwięcej integracji psuje się nie w samym przepływie, tylko wcześniej, na etapie konfiguracji. Brakuje dokładnego issuer URL, ktoś wpisuje redirect URI z literówką albo zbyt wcześnie decyduje, jakie scope’y będą potrzebne. Ja zwykle zaczynam od zebrania poniższych elementów.
| Element | Po co go potrzebujesz | Na co uważać |
|---|---|---|
| Issuer URL | Identyfikuje dostawcę tożsamości | Musi zgadzać się z `iss` w tokenie |
| `client_id` | Rozpoznaje Twoją aplikację | To nie jest sekret, ale musi być spójny z rejestracją |
| `client_secret` lub inny mechanizm uwierzytelnienia klienta | Potwierdza tożsamość aplikacji przy wymianie kodu | Trzymaj wyłącznie po stronie backendu |
| Redirect URI | Odbiera odpowiedź po logowaniu | Wymaga dokładnego dopasowania, łącznie ze schematem i ścieżką |
| Zakresy dostępu | Określają, jakie dane są potrzebne | Na start zwykle wystarcza `openid profile email` |
| JWKS URI | Daje publiczne klucze do weryfikacji podpisu | Sprawdź, czy aplikacja obsługuje rotację kluczy |
| Sesja aplikacji | Utrzymuje zalogowanego użytkownika po powrocie z providera | Najbezpieczniej opierać ją o `HttpOnly` i `Secure` cookie |
W praktyce discovery document bardzo upraszcza start, bo z jednego endpointu pobierasz adres autoryzacji, token endpoint, UserInfo i publiczne klucze. Mając te dane, można już przejść do samego przepływu logowania, a tam liczy się kolejność kroków.
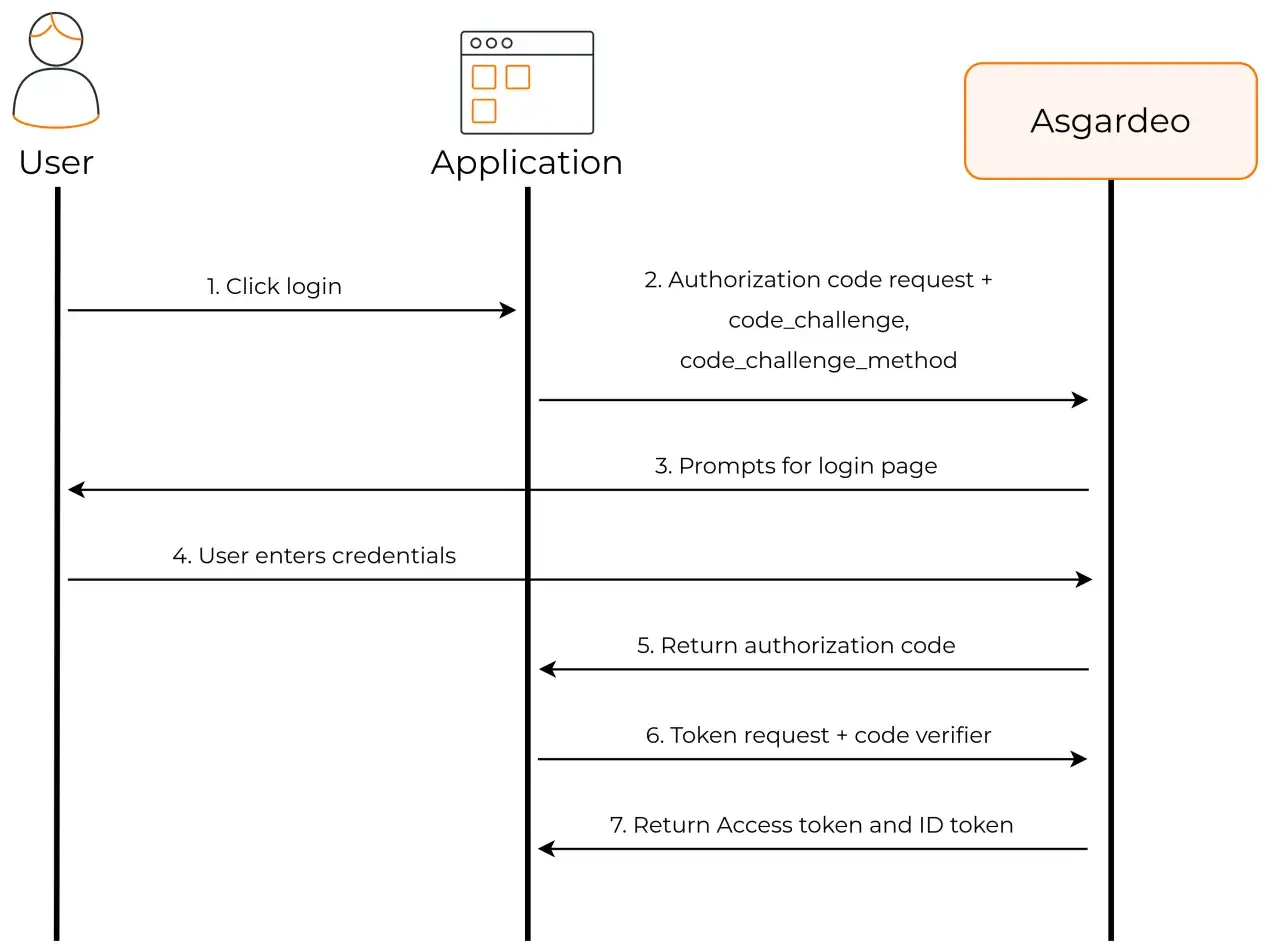
Jak wygląda poprawne podłączenie krok po kroku
Najbezpieczniejszy i najczęściej stosowany model to Authorization Code Flow z PKCE. W 2026 to właśnie ten wariant traktuję jako punkt wyjścia dla nowych wdrożeń, bo jest lepiej dopasowany do aplikacji webowych, SPA i mobilnych niż starsze, uproszczone ścieżki.
- Pobieram discovery document z adresu `/.well-known/openid-configuration` i czytam z niego endpointy oraz wymagane parametry.
- Rejestruję aplikację u dostawcy tożsamości i wpisuję dokładne redirect URI dla środowiska testowego oraz produkcyjnego.
- Wysyłam użytkownika na authorization endpoint z `response_type=code`, zakresem `openid` i dodatkowymi scope’ami, jeśli są potrzebne.
- Dodaję `state`, żeby chronić przepływ przed podszyciem się pod odpowiedź, oraz `nonce`, żeby związać odpowiedź z konkretnym żądaniem logowania.
- Generuję PKCE: `code_verifier` po stronie aplikacji i `code_challenge` w żądaniu autoryzacji.
- Po powrocie użytkownika odbieram kod autoryzacyjny na redirect URI i wymieniam go na tokeny w token endpoint.
- Waliduję `id_token`, podpis, issuer, audience, daty ważności i dopiero wtedy tworzę lokalną sesję aplikacji.
- Jeśli potrzebuję dodatkowych danych profilu, dociągam je z UserInfo endpoint, ale tylko wtedy, gdy ma to sens biznesowy.
To jest ścieżka, którą wybieram prawie zawsze, bo daje najlepszy kompromis między bezpieczeństwem a prostotą utrzymania. Dalej trzeba już tylko dopasować ją do typu aplikacji, bo inaczej wdraża się backend webowy, a inaczej SPA albo aplikację mobilną.
Jak dobrać wariant do weba, SPA i mobile
Jedna rzecz, którą często widzę w projektach, to próba wrzucenia identycznej integracji do każdego rodzaju klienta. To zwykle kończy się obejściami, które działają w demo, a potem psują bezpieczeństwo albo UX. Ja wolę dobrać przepływ do architektury od samego początku.
| Typ aplikacji | Najlepszy wariant | Czego unikać |
|---|---|---|
| Klasyczna aplikacja webowa z backendem | Authorization Code Flow, wymiana kodu po stronie serwera, sesja oparta o cookie | Trzymania tokenów w JavaScript po stronie przeglądarki |
| SPA | Authorization Code Flow z PKCE, najlepiej z BFF, jeśli masz kontrolę nad backendem | LocalStorage jako magazynu tokenów i starych skrótów bez PKCE |
| Aplikacja mobilna | System browser, PKCE i osobny redirect scheme dla aplikacji | Własnych, wbudowanych przeglądarek do logowania |
| Integracja server-to-server | Zwykle OAuth 2.0, nie OIDC, bo nie ma użytkownika końcowego | Wpychania logowania użytkownika tam, gdzie chodzi tylko o dostęp aplikacji |
Jeśli masz wpływ na architekturę, BFF zwykle upraszcza życie. Przeglądarka dostaje tylko bezpieczną sesję, a tokeny zostają po stronie backendu. To nie jest rozwiązanie obowiązkowe, ale w wielu polskich projektach SaaS i panelach administracyjnych po prostu redukuje ryzyko bez większej straty wygody. Po wybraniu wariantu trzeba już dopiąć walidację, bo to ona odróżnia działające logowanie od prawdziwie bezpiecznego logowania.
Jak zweryfikować tokeny i utrzymać sesję
Tu zaczyna się fragment, w którym wiele integracji wygląda poprawnie, ale wciąż jest słaba od środka. Sama obecność JWT nie znaczy nic. Token trzeba zweryfikować, a nie tylko odczytać. Nie ufam tokenowi, dopóki nie sprawdzę podpisu i podstawowych claimów.
| Element tokenu lub sesji | Co sprawdzam | Dlaczego to ważne |
|---|---|---|
| `iss` | Czy issuer jest dokładnie tym, którego oczekuję | Chroni przed tokenami z obcego środowiska lub innego providera |
| `aud` | Czy token jest wystawiony dla mojego klienta | Token dla innej aplikacji nie może być akceptowany |
| `sub` | Stabilny identyfikator użytkownika | Na nim buduję wewnętrzne konto, nie na e-mailu |
| `exp`, `iat`, `nbf` | Ważność i moment wystawienia | Nie przyjmuję starych albo jeszcze nieważnych tokenów |
| `nonce` | Zgodność z żądaniem logowania | Łączy odpowiedź z konkretnym cyklem autoryzacji |
| Podpis JWT | Czy token został podpisany poprawnym kluczem z JWKS | Bez tego każdy fałszywy token przechodziłby jak prawdziwy |
Po stronie sesji wybieram rozwiązanie możliwie proste: krótkożyjąca sesja aplikacji, najlepiej w `HttpOnly` cookie, z rozsądnym czasem życia i odświeżaniem tylko tam, gdzie jest to potrzebne. Jeśli muszę korzystać z refresh tokenów, trzymam je po stronie serwera i pilnuję rotacji. W praktyce daje to dużo lepszą kontrolę niż przechowywanie wszystkiego w przeglądarce.
Jest jeszcze jedna rzecz, o której łatwo zapomnieć: wylogowanie. Nie każdy dostawca obsługuje je tak samo, więc zawsze rozdzielam lokalne zakończenie sesji od wylogowania globalnego. Lokalna sesja musi zniknąć niezależnie od tego, czy provider ma własny end-session endpoint. To ważne, bo od tego zależy spójność zachowania aplikacji w realnym użyciu.
Najczęstsze błędy, które psują integrację
Przy wdrożeniach widzę kilka powtarzalnych błędów. Większość z nich nie wynika ze złej technologii, tylko z pośpiechu albo z założenia, że „skoro działa w testach, to jest dobrze”. To akurat w integracjach tożsamości bywa najdroższe założenie.
- Pomijanie `state` i `nonce`.
- Ręczne wpisywanie endpointów zamiast używania discovery document.
- Walidowanie tylko podpisu, bez sprawdzenia `iss` i `aud`.
- Mylenie access tokenu z ID tokenem.
- Trzymanie tokenów w `localStorage`, choć nie jest to najbezpieczniejszy magazyn dla takich danych.
- Używanie implicit flow w nowym projekcie, mimo że nowsze zalecenia bezpieczeństwa prowadzą w stronę Authorization Code Flow z PKCE.
- Brak obsługi rotacji kluczy po stronie dostawcy.
- Niedokładne redirect URI, które w jednym środowisku działają, a w innym dają trudny do zdiagnozowania błąd.
Ja zawsze traktuję te punkty jako checklistę awaryjną. Jeśli choć jeden z nich nie jest domknięty, integracja jeszcze nie jest gotowa do produkcji. I właśnie dlatego przed przełączeniem ruchu warto zrobić ostatni, praktyczny przegląd konfiguracji.
Na produkcji wygrywa twarda walidacja i krótka sesja
Przed wdrożeniem na produkcję sprawdzam rzeczy, które na pierwszy rzut oka nie są efektowne, ale później robią największą różnicę. Najlepiej działa nie najprostszy, tylko najstabilniejszy wariant integracji.
- Testuję logowanie na czystej przeglądarce, w trybie prywatnym i na urządzeniu mobilnym.
- Sprawdzam, czy aplikacja poprawnie odrzuca tokeny z nieznanym issuerem.
- Weryfikuję, czy rotacja kluczy nie wymaga ręcznego restartu usługi.
- Ustalam rozsądny czas życia sesji aplikacji, najczęściej w przedziale 15-30 minut dla bardziej wrażliwych paneli, albo dłużej tam, gdzie polityka bezpieczeństwa na to pozwala.
- Loguję błędy autoryzacji w sposób, który pomaga diagnozować problemy, ale nie ujawnia tokenów ani danych wrażliwych.
- Próbuję scenariuszy awaryjnych: brak dostępu do providera, cofnięcie zgody, wygaśnięcie sesji, zmiana hasła i ponowne logowanie.
Jeśli chcesz podłączyć OpenID Connect bez późniejszych niespodzianek, trzymaj się jednej zasady: najpierw poprawny przepływ, potem wygoda. Dobrze skonfigurowane logowanie daje użytkownikowi prosty start, a zespołowi technicznemu spokój przy utrzymaniu. I właśnie o to chodzi w tej integracji: o standard, który upraszcza życie zamiast dokładać kolejny własny mechanizm do utrzymania.