
W JavaScript var to starszy sposób deklarowania zmiennych, który wciąż pojawia się w projektach utrzymaniowych i w materiałach dla początkujących. Najważniejsze jest zrozumienie, jak działa jego zakres, czym różni się od nowszych deklaracji oraz gdzie potrafi zaskoczyć. W praktyce to wiedza, która pomaga czytać starszy kod i nie wprowadzać błędów przy drobnych poprawkach.
Najkrócej: to starszy sposób deklarowania zmiennych, który warto znać głównie przy pracy ze starszym kodem
- Działa w zasięgu funkcji albo globalnym, a nie blokowym.
- Deklaracja jest podnoszona, więc zmienna istnieje wcześniej niż sama linia przypisania.
- W nowym kodzie zwykle wybieram
letalboconst. - Najwięcej problemów powoduje mylenie zakresu bloku z zakresem funkcji.
- W 2026 roku najczęściej spotyka się go w starszych aplikacjach i bibliotekach.
Co oznacza ta starsza składnia w JavaScript
Najprościej ujmując, chodzi o sposób tworzenia zmiennej, który był standardem zanim upowszechniły się nowocześniejsze deklaracje. Taki zapis nie jest zły sam w sobie, ale jego zachowanie bywa mniej intuicyjne niż w nowszych konstrukcjach. Ja traktuję go jako element historii języka, który nadal trzeba rozumieć, bo realne projekty rzadko są pisane od zera.
Ważne jest też to, że sama nazwa zmiennej nie mówi jeszcze wszystkiego o jej zachowaniu. W tym modelu liczy się nie tylko to, że zmienna istnieje, ale też gdzie jest widoczna i kiedy faktycznie dostaje wartość. To właśnie dlatego początkujący często czują, że kod „zachowuje się sam” w sposób, którego nie da się łatwo przewidzieć.
Gdy rozumiem ten mechanizm, łatwiej mi ocenić, czy mam do czynienia z prostym fragmentem, czy ze starszą częścią aplikacji wymagającą ostrożności. To prowadzi prosto do pytania, dlaczego ta składnia wciąż w ogóle pojawia się w nowych analizach i poradnikach.
Dlaczego wciąż spotykam ją w projektach
W 2026 roku najczęściej widzę ten styl deklarowania zmiennych nie w świeżym kodzie, ale w aplikacjach utrzymywanych przez lata, w starszych snippetach i w materiałach, które krążą po sieci od dawna. Takie fragmenty nie znikają, bo software żyje długo: ktoś poprawia jedną funkcję, ktoś inny dokleja nową integrację i stary styl zostaje na miejscu.
Najczęstsze scenariusze są bardzo przyziemne:
- stare aplikacje frontendowe, które nie przeszły pełnej modernizacji,
- skrypty pomocnicze uruchamiane po stronie przeglądarki albo serwera,
- kody z tutoriali sprzed lat, które ktoś wkleił do produkcji bez refaktoru,
- biblioteki i moduły, których nie opłaca się przepisywać tylko po to, by zmienić styl deklaracji.
To ma znaczenie praktyczne, bo umiejętność czytania starszego kodu często decyduje o tempie pracy bardziej niż znajomość najnowszych frameworków. Żeby dobrze ocenić, kiedy taki zapis jest problemem, trzeba przejść do dwóch cech, które najbardziej zmieniają jego zachowanie: zakresu i hoistingu.
Jak działa zakres i podnoszenie deklaracji w praktyce
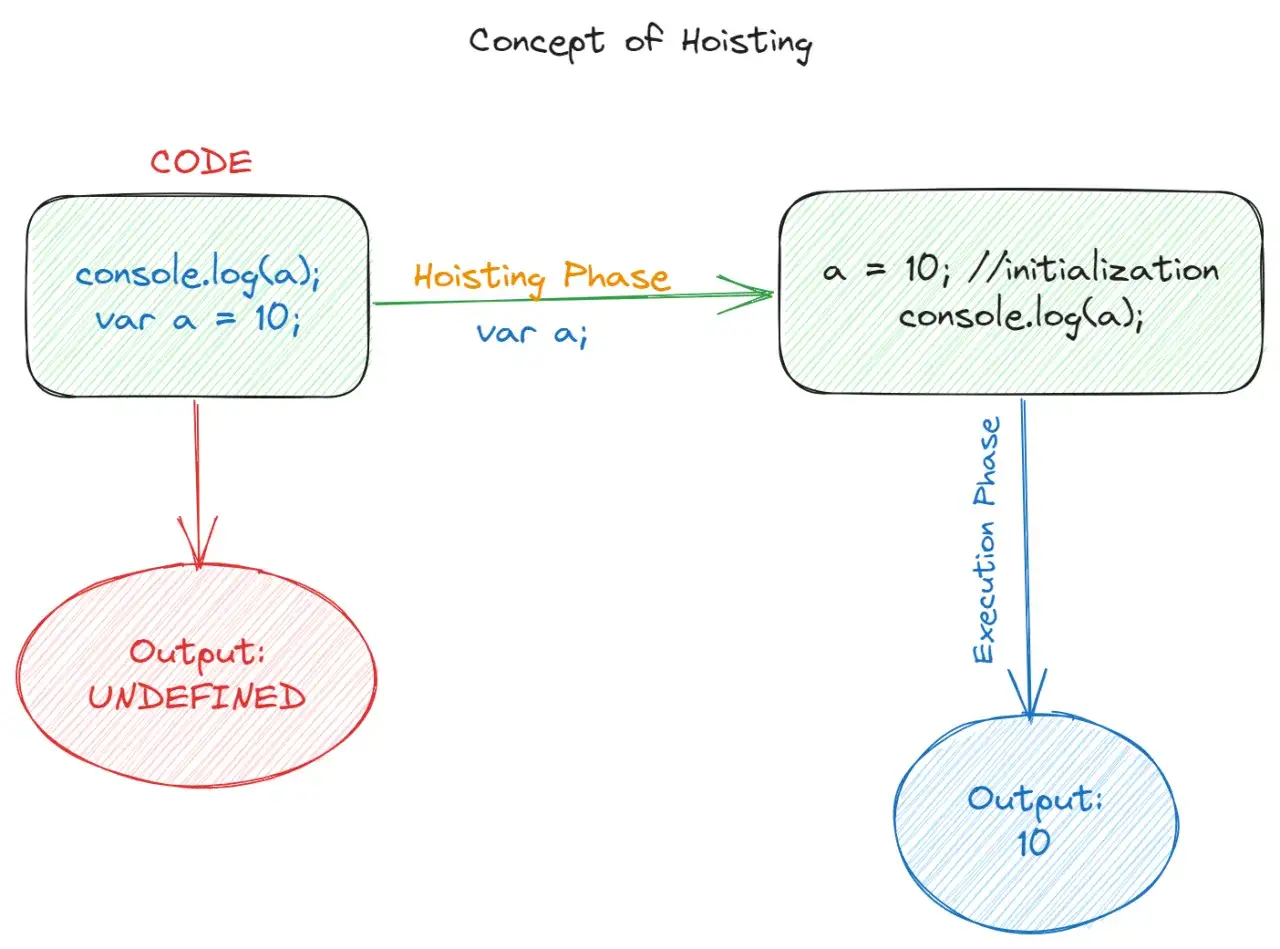
Tu zaczynają się rzeczy, które najbardziej mylą osoby uczące się programowania. W tym modelu zmienna nie zachowuje się blokowo, tylko „podąża” za funkcją lub całym kontekstem globalnym. Do tego dochodzi podnoszenie deklaracji, czyli sytuacja, w której sam fakt istnienia zmiennej jest znany wcześniej niż linia, na której ją zapisujesz.
console.log(counter);
var counter = 3;Ten przykład jest prosty, ale dobrze pokazuje sedno: deklaracja jest dostępna wcześniej, natomiast przypisanie wartości nadal dzieje się dopiero w miejscu, w którym je napisałeś. W efekcie pierwsze odwołanie nie kończy się błędem, tylko daje wynik, który dla początkujących wygląda jak bug znikąd. Właśnie dlatego wolę tłumaczyć to jako „podniesienie deklaracji, ale nie przypisania”, bo to najuczciwszy skrót myślowy.
Druga pułapka jest jeszcze bardziej zdradliwa: blok nie zatrzymuje takiej zmiennej wewnątrz siebie. W nowocześniejszym zapisie coś takiego byłoby od razu łatwiejsze do przewidzenia, bo zmienna żyje tylko w obrębie bloku. To pokazuje, jak mocno różni się stare zachowanie od współczesnych standardów i dlaczego w praktyce warto to odróżniać od nowszych deklaracji.
Gdy już to widać, znacznie łatwiej zestawić ten mechanizm z let i const, czyli z tym, co dziś dominuje w większości nowych projektów.
Jak wypada na tle let i const
Jeżeli miałbym ująć różnicę w jednym zdaniu, powiedziałbym tak: w nowym kodzie chcę przewidywalności, a nie historycznej zgodności za wszelką cenę. Dlatego w praktyce najpierw patrzę na to, czy wartość ma się zmieniać, a dopiero potem wybieram odpowiednią deklarację.
| Cecha | Starsza składnia | let |
const |
|---|---|---|---|
| Zakres | Funkcja lub globalny | Blokowy | Blokowy |
| Zmiana wartości | Tak | Tak | Nie |
| Zachowanie przed deklaracją | Może zaskoczyć przez podniesienie | Brak bezpiecznego dostępu | Brak bezpiecznego dostępu |
| Najlepsze zastosowanie | Utrzymanie starszego kodu | Zmienne, które będą się zmieniać | Wartości, które nie powinny być nadpisane |
W mojej ocenie ta tabela dobrze oddaje praktykę: jeśli tworzysz nowy kod, domyślnym wyborem jest zwykle const, a let wchodzi wtedy, gdy realnie potrzebujesz późniejszego przypisania. Taki podział jest prostszy do utrzymania i trudniej w nim o przypadkowe nadpisania. Kiedy ten kontrast jest już jasny, dużo łatwiej wskazać błędy, które w starych fragmentach pojawiają się najczęściej.
Najczęstsze błędy, które naprawdę bolą
Przy takim mechanizmie najwięcej szkód robi nie sam zapis, tylko błędne założenia. Widziałem wielokrotnie sytuacje, w których ktoś zakładał blokowy zakres, a potem przez kilka godzin szukał przyczyny dziwnego nadpisania wartości poza warunkiem albo pętlą.
- Mylenie zakresu bloku z zakresem funkcji - kod wygląda niewinnie, ale zmienna wychodzi dalej, niż oczekujesz.
-
Oczekiwanie błędu tam, gdzie pojawia się
undefined- to rozbraja debugowanie, bo problem nie krzyczy od razu. - Powtarzanie tej samej nazwy - w starszym stylu łatwo o kod, który działa, ale jest trudny do utrzymania.
- Przenoszenie fragmentu bez sprawdzenia kontekstu - po skopiowaniu logika może zacząć zachowywać się inaczej niż w oryginale.
Najbardziej kosztowny błąd jest zwykle banalny: ktoś patrzy na działający fragment i zakłada, że na pewno jest napisany „bezpiecznie”. Tymczasem w starym kodzie poprawność działania nie zawsze oznacza dobrą architekturę, a reguły widoczności potrafią ukryć problem aż do produkcji.
To prowadzi do praktycznego pytania, które zawsze zadaję sobie przy refaktorze: zostawić ten zapis, czy jednak go przepisać.
Kiedy przepisać kod, a kiedy zostawić go w spokoju
Nie przepisywałbym wszystkiego automatycznie tylko dlatego, że da się to zrobić „ładniej”. W realnym projekcie liczy się koszt zmiany, ryzyko regresji i to, czy fragment w ogóle jeszcze wymaga aktywnej pracy. Jeśli dotykam małego, stabilnego kawałka legacy i zmiana niczego nie poprawia, czasem lepiej zostawić go w spokoju.
Przepisać warto wtedy, gdy:
- zmieniasz logikę w obrębie warunków albo pętli i chcesz ograniczyć zakres do bloku,
- w kodzie pojawiają się trudne do wyjaśnienia nadpisania,
- zespół trzyma jeden nowoczesny standard i warto go konsekwentnie utrzymać,
- fragment i tak przechodzi większy refaktor, więc koszt poprawki jest niski.
Zostawić można wtedy, gdy poprawiasz coś minimalnie, a stary styl nie wpływa na czytelność ani bezpieczeństwo. Ja patrzę na to bardzo pragmatycznie: jeśli ryzyko przepisywania jest większe niż zysk, nie robię z tego ideologii. Jeśli jednak kod ma jeszcze długo żyć, lepiej stopniowo przejść na prostsze reguły i zamknąć temat zanim problem urośnie.
Jak czytam ten element w starszym projekcie bez zgadywania
Moja praktyczna kolejność jest prosta: najpierw sprawdzam zakres, potem patrzę na miejsca możliwego nadpisania, a dopiero na końcu decyduję, czy warto ruszać cały fragment. Taki porządek oszczędza czas, bo nie walczę z objawami, tylko z przyczyną.
- Jeśli zmienna ma żyć tylko w jednym bloku, wolę przepisać ją na nowoczesny zapis.
- Jeśli kod jest stabilny i rzadko dotykany, nie robię refaktoru dla samej elegancji.
- Jeśli fragment ma wiele warunków i pętli, dodatkowa czytelność zwykle szybko się zwraca.
- Jeśli pracuję zespołowo, konsekwencja stylu jest ważniejsza niż osobiste preferencje.
W praktyce ten temat sprowadza się do jednej decyzji: rozumieć starszy mechanizm na tyle dobrze, by nie dać się nim zaskoczyć, ale nie traktować go jako domyślnego wyboru w nowym kodzie. Gdy nie muszę utrzymywać starego zachowania, wybieram prostsze i bardziej przewidywalne deklaracje, a ten starszy zapis zostawiam tam, gdzie naprawdę ma sens.