
Integracja danych przestaje być dodatkiem, kiedy firma ma osobne systemy sprzedaży, CRM, aplikację produktową i logi techniczne. Bez uporządkowanego przepływu danych raporty zaczynają się rozjeżdżać, a zespoły tracą czas na ręczne poprawki zamiast na analizę i decyzje. W tym artykule pokazuję, jak działa ETL, kiedy ten model ma sens, jak wygląda od strony kodu i gdzie najczęściej psuje się jakość danych.
Najważniejsze rzeczy, które warto wiedzieć o przepływie danych
- ETL porządkuje dane z wielu źródeł i przygotowuje je do analityki, raportowania lub dalszego przetwarzania.
- Najpierw dane się pobiera, potem czyści i przekształca, a dopiero na końcu ładuje do systemu docelowego.
- W chmurze coraz częściej wybiera się ELT, ale klasyczny model nadal ma sens tam, gdzie liczy się kontrola, zgodność i jakość wejścia.
- W kodzie ważniejsze od samej technologii są: testy, idempotencja, monitoring i obsługa zmian w schemacie.
- Najwięcej problemów robią: brak walidacji, monolityczne joby, słabe logowanie i brak planu na błędy danych.
Czym jest ETL i kiedy naprawdę ma sens
To po prostu proces, w którym dane są pobierane z wielu źródeł, oczyszczane, przekształcane i ładowane do miejsca docelowego, najczęściej hurtowni danych albo warstwy analitycznej. W praktyce nie chodzi o samą technikę przenoszenia rekordów, tylko o zbudowanie takiego przepływu, żeby informacje były spójne, porównywalne i gotowe do użycia bez ręcznej obróbki.
Ten model ma sens szczególnie wtedy, gdy źródła są różne jakościowo: jedno API zwraca dane w JSON-ie, drugi system trzyma je w tabelach, a trzeci dostarcza pliki CSV raz dziennie. Wtedy bez warstwy transformacji dostajesz chaos, a nie wspólny obraz biznesu. Z mojego punktu widzenia właśnie tu ETL wygrywa z improwizacją, bo wymusza porządek i daje jedno miejsce, w którym ustalasz reguły biznesowe.
Najczęściej używa się go w raportowaniu, finansach, e-commerce, marketingu i wszędzie tam, gdzie jedna nieścisłość w danych potrafi zepsuć cały dashboard. To nie jest rozwiązanie tylko dla dużych organizacji. Mniejsze zespoły też szybko czują różnicę, kiedy zamiast ręcznie sklejać eksporty z kilku systemów mają jeden stabilny proces. I właśnie dlatego następny krok to zrozumienie, jak ten przepływ wygląda od środka.
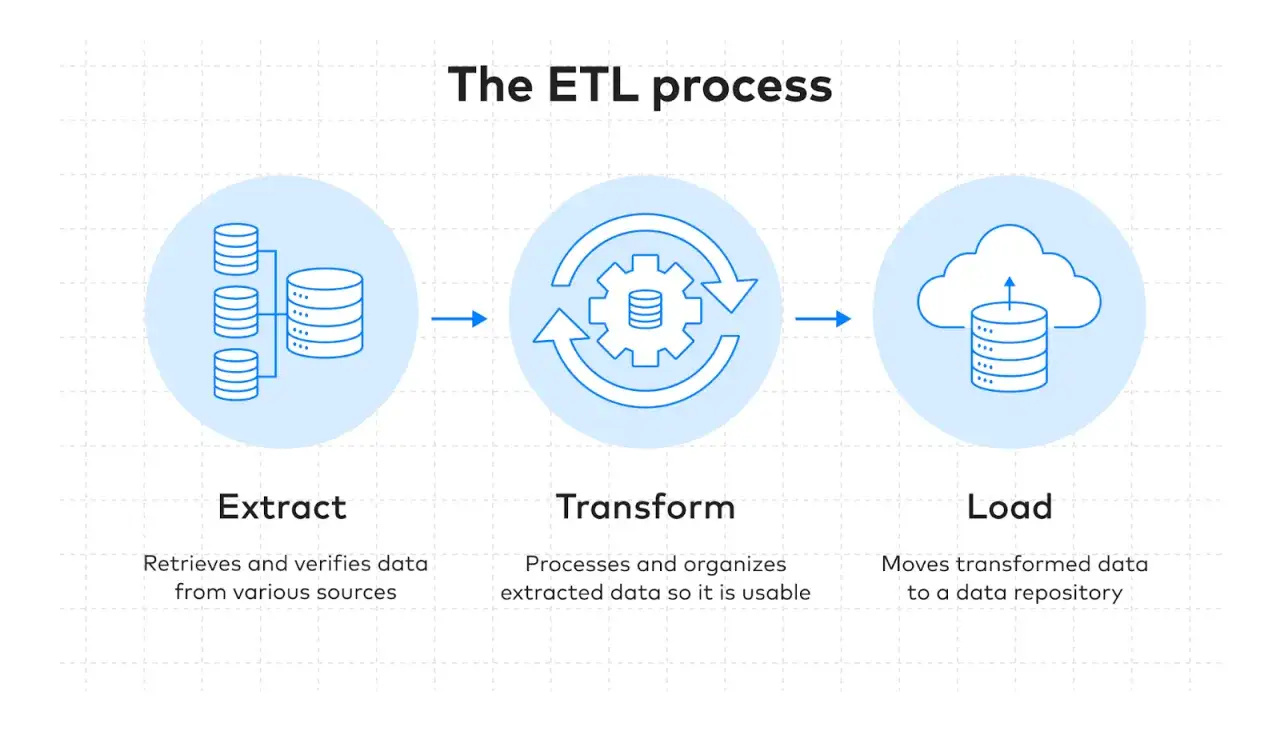
Jak wygląda pipeline danych krok po kroku
W dobrze zaprojektowanym pipeline dane nie „przelatują” przypadkowo z punktu A do punktu B. Każdy etap ma swoją rolę i własne ograniczenia, a pominięcie jednego z nich zwykle mści się później w raportach albo w kosztach utrzymania.
- Ekstrakcja pobiera dane z API, baz danych, plików, kolejek zdarzeń albo systemów SaaS. Tu liczy się stabilność połączeń, kontrola zakresu danych i obsługa błędów sieciowych.
- Staging to warstwa buforowa, czyli miejsce, w którym dane lądują chwilowo przed obróbką. Dzięki temu łatwiej je kontrolować i odtwarzać proces po awarii.
- Transformacja porządkuje formaty, usuwa duplikaty, mapuje pola i stosuje reguły biznesowe. To tutaj z surowych rekordów powstaje dane, którym można ufać.
- Ładowanie zapisuje wynik do hurtowni, lakehouse albo innego repozytorium docelowego. Na tym etapie ważne są wydajność, spójność i strategia aktualizacji.
W praktyce kluczowe jest nie to, czy pipeline ma trzy, cztery czy pięć kroków, tylko czy potrafi bezpiecznie przetwarzać dane także wtedy, gdy źródło zmieni format albo opóźni wysyłkę. Tu często pojawia się też pojęcie CDC, czyli change data capture, mechanizmu wykrywającego zmiany w źródle zamiast przepisywania całych tabel. To oszczędza czas i pieniądze, zwłaszcza przy dużych wolumenach. Kiedy rozumiesz ten mechanizm, łatwiej ocenić, czy lepszy będzie klasyczny model, czy podejście bardziej chmurowe.
ETL a ELT czyli wybór architektury
Różnica między tymi modelami jest prostsza, niż wygląda w prezentacjach sprzedażowych. W ETL najpierw przetwarzasz dane poza systemem docelowym, a dopiero potem je ładujesz. W ELT ładujesz dane szybciej do hurtowni, a transformacje wykonujesz już na miejscu, korzystając z mocy nowoczesnej platformy analitycznej.
Jeśli miałbym wskazać praktyczne kryterium wyboru, patrzyłbym przede wszystkim na trzy rzeczy: gdzie leży odpowiedzialność za jakość danych, jak duży jest wolumen i kto będzie to utrzymywał. W modelu klasycznym więcej kontroli masz przed załadowaniem. W modelu ELT więcej elastyczności dostajesz po stronie hurtowni i zespołu analitycznego.
| Cecha | ETL | ELT |
|---|---|---|
| Miejsce transformacji | Poza systemem docelowym | W systemie docelowym |
| Największa zaleta | Silna kontrola jakości przed zapisem | Duża elastyczność i prostsze skalowanie |
| Typowe zastosowanie | Raporty finansowe, procesy regulowane, integracje o wysokiej kontroli | Nowoczesne hurtownie w chmurze, analityka produktowa, szybkie iteracje |
| Ryzyko | Węższa przepustowość przy ciężkich transformacjach | Zaśmiecenie hurtowni surowymi danymi, jeśli brak zasad porządkowania |
W 2026 roku wiele zespołów wybiera ELT, bo chmura dobrze skaluje przetwarzanie, ale to nie znaczy, że klasyczny model zniknął. Tam, gdzie liczy się audyt, zgodność i przewidywalność, lepiej mieć transformację pod własną kontrolą. Właśnie dlatego projekt architektury powinien wynikać z wymagań biznesowych, a nie z mody na konkretne narzędzie. I tu wchodzi temat kodu, bo nawet najlepsza architektura bez porządnej implementacji szybko się sypie.
Co w tym wszystkim robi kod
Od strony developerskiej taki system to zwykle nie jeden skrypt, tylko zestaw małych elementów, które razem robią robotę. Najczęściej spotykam połączenie SQL, Pythona, narzędzia do orkiestracji i warstwy testów. SQL dobrze sprawdza się w prostych transformacjach i agregacjach, Python w integracjach, walidacji i pracy z API, a orkiestrator pilnuje kolejności zadań, retry i harmonogramu.
W praktyce kod w pipeline danych powinien robić kilka rzeczy jednocześnie, ale bez chaosu: pobierać dane, walidować je, logować przebieg, obsługiwać błędy i nie tworzyć duplikatów przy ponownym uruchomieniu. Idempotencja oznacza właśnie to, że ten sam proces można uruchomić ponownie bez psucia wyniku. To nie jest detal, tylko warunek, żeby awaria nie kończyła się ręcznym sprzątaniem pół nocy.
| Element | Po co jest potrzebny | Kiedy szczególnie pomaga |
|---|---|---|
| SQL | Transformacje, łączenie tabel, agregacje | Przy pracy na hurtowniach i prostych regułach biznesowych |
| Python | Integracje, walidacja, niestandardowa logika | Przy API, nietypowych formatach i złożonych kontrolach jakości |
| Orkiestrator | Uruchamianie kroków we właściwej kolejności | Gdy jeden etap zależy od wyniku poprzedniego |
| Testy danych | Wykrywanie braków, duplikatów i anomalii | Gdy raporty mają być wiarygodne, a nie tylko „działać” |
| Monitoring | Alerty, logi, metryki opóźnień | Gdy proces ma działać bez ciągłego nadzoru człowieka |
Jeżeli pipeline ma być naprawdę użyteczny, kod powinien też uwzględniać zmianę schematu, czyli sytuację, w której źródło dodaje lub usuwa kolumny. To właśnie tutaj dużo projektów potyka się o własny sukces, bo pierwsza wersja działa świetnie, a druga jest już trudna do utrzymania. Następna sekcja pokazuje, gdzie dokładnie te błędy wychodzą na jaw najczęściej.
Najczęstsze błędy, które psują jakość danych
Najczęściej problem nie leży w technologii, tylko w założeniach. Zespół zakłada, że źródło nigdy się nie zmieni, że dane przyjdą zawsze na czas i że jeden duży job będzie prostszy niż kilka mniejszych. W teorii brzmi to wygodnie, w praktyce kończy się kruchym systemem.
- Brak walidacji przed zapisem powoduje, że błędne rekordy trafiają do hurtowni i psują raporty u wszystkich odbiorców.
- Monolityczny proces jest trudny do debugowania, bo przy awarii nie wiadomo, który krok zawiódł.
- Brak monitoringu sprawia, że opóźnienia wychodzą dopiero wtedy, gdy ktoś zauważy brak danych w dashboardzie.
- Pomijanie wersjonowania schematu kończy się błędami po stronie integracji, zwłaszcza gdy źródła rozwijają się niezależnie.
- Nieprzemyślana logika duplikatów produkuje podwójne rekordy, a później trzeba je ręcznie odkręcać.
Moim zdaniem największym błędem jest traktowanie przepływu danych jak jednorazowego skryptu. To jest system, który żyje razem z produktem, źródłami i zespołem analitycznym. Jeśli nie ma testów, alertów i jasnych reguł jakości, to nawet dobre dane po kilku miesiącach zaczynają wyglądać podejrzanie. Dlatego lepiej od razu budować rozwiązanie tak, żeby dało się je utrzymać bez heroizmu.
Jak zbudować rozwiązanie, które da się utrzymać
Jeśli miałbym rozpisać sensowny plan wdrożenia, zacząłbym od prostych, ale twardych zasad. Najpierw trzeba ustalić, co jest źródłem prawdy, jakie pola są obowiązkowe i jakie błędy blokują zapis, a jakie można tylko oznaczyć ostrzeżeniem. To brzmi podstawowo, ale właśnie takie decyzje decydują o tym, czy system będzie stabilny.
- Zdefiniuj kontrakt danych, czyli minimalny zestaw pól, formatów i reguł jakości.
- Rozdziel ekstrakcję, transformację i ładowanie tak, by każdy krok dało się uruchomić oraz przetestować osobno.
- Dodaj mechanizm ponawiania prób i zapisuj stan przetwarzania, żeby nie tracić pracy po awarii.
- Wprowadź testy jakości danych, nie tylko testy techniczne kodu.
- Monitoruj opóźnienia, brakujące rekordy i zmiany schematu, zanim zauważy je biznes.
- Przy większej skali stawiaj na przyrostowe przetwarzanie zamiast pełnego kopiowania wszystkiego przy każdym uruchomieniu.
Warto też pamiętać o kosztach. Im więcej danych przetwarzasz od zera, tym droższy staje się cały pipeline. Przyrostowe ładowanie zwykle jest tańsze i szybsze, ale wymaga lepszego śledzenia zmian. To właśnie ten kompromis najczęściej decyduje o architekturze, a nie sama sympatia do konkretnego narzędzia. Kiedy to poukładasz, zostaje już tylko jedno pytanie: co tak naprawdę daje dobrze zrobiony system w dłuższym horyzoncie?
Co zostaje po dobrym projekcie danych
Najlepszy efekt nie polega na tym, że pipeline działa raz czy dwa. Chodzi o to, że zespół przestaje ratować raporty ręcznie, a dane zaczynają być przewidywalne, porównywalne i szybkie do użycia. To duża różnica, bo wtedy analitycy nie tracą czasu na czyszczenie chaosu, tylko naprawdę pracują na informacjach.
Jeśli miałbym zostawić jedną praktyczną myśl, to taką: dobry przepływ danych jest bardziej o dyscyplinie niż o magii narzędzi. Narzędzie pomaga, ale dopiero jasne reguły, testy, monitoring i rozsądny podział odpowiedzialności sprawiają, że system skaluje się bez bólu. Gdy te elementy są na miejscu, łatwiej dodać nowe źródło, zmienić schemat albo przejść z prostego modelu na bardziej zaawansowaną architekturę.
Właśnie dlatego przy projektowaniu integracji danych myślę przede wszystkim o utrzymaniu, a dopiero później o efektownych nazwach technologii. Jeśli proces ma wspierać decyzje biznesowe, musi być odporny na zmianę, błędy i rosnący wolumen. Wszystko inne jest dodatkiem, nie fundamentem.