
W aplikacjach webowych i systemach biznesowych trudno uciec od prostego schematu pracy na danych: coś tworzysz, potem to odczytujesz, zmieniasz albo usuwasz. Ten model porządkuje backend, API i bazę danych, a przy okazji ułatwia czytanie cudzego kodu i ocenę, czy architektura nie jest przekombinowana. Poniżej rozkładam go na praktyczne elementy: od definicji, przez HTTP i REST, aż po typowe błędy i sytuacje, w których sam model zaczyna być za mały.
Najważniejsze fakty o CRUD w praktyce programistycznej
- CRUD oznacza cztery podstawowe operacje na danych: tworzenie, odczyt, aktualizację i usuwanie.
- W API najczęściej mapuje się je na POST, GET, PUT lub PATCH oraz DELETE.
- To nie jest pełna architektura aplikacji, tylko podstawowy wzorzec pracy na zasobach.
- Dobrze zaprojektowany CRUD uwzględnia walidację, uprawnienia, spójność danych i sensowne kody odpowiedzi.
- W złożonych produktach operacje biznesowe często są ważniejsze niż gołe „create/read/update/delete”.
Co naprawdę oznacza CRUD i dlaczego w kodzie wraca tak często
CRUD to skrót od Create, Read, Update, Delete, czyli tworzenia, odczytu, aktualizacji i usuwania danych. Ja traktuję go jako wspólny język dla programisty backendu, frontendu i osoby projektującej bazę danych, bo wszystkie te warstwy muszą w końcu obsłużyć ten sam cykl życia informacji. To nie jest termin zarezerwowany wyłącznie dla baz SQL - chodzi szerzej o operacje na trwałym stanie: rekordach, dokumentach, zasobach API, a czasem nawet o danych oznaczonych jako „ukryte” zamiast fizycznie skasowanych.
W praktyce taki model pojawia się wszędzie tam, gdzie system zarządza obiektami: użytkownikami, produktami, zamówieniami, artykułami, plikami czy zadaniami. W prostych panelach administracyjnych CRUD bywa wręcz całą historią produktu. W bardziej złożonych systemach jest fundamentem, ale nie końcem opowieści, bo nad samą strukturą danych zaczyna dominować logika biznesowa, uprawnienia i reguły przepływu stanu.
Warto też pamiętać o jednej rzeczy, którą łatwo przegapić na początku: „Delete” nie zawsze oznacza fizyczne usunięcie rekordu. Często lepszy jest soft delete, czyli oznaczenie elementu jako usuniętego, ale zachowanie go w systemie z powodów audytowych, prawnych albo analitycznych. Gdy to już jasne, najważniejsze staje się pytanie, jak ten model przekłada się na HTTP i REST.
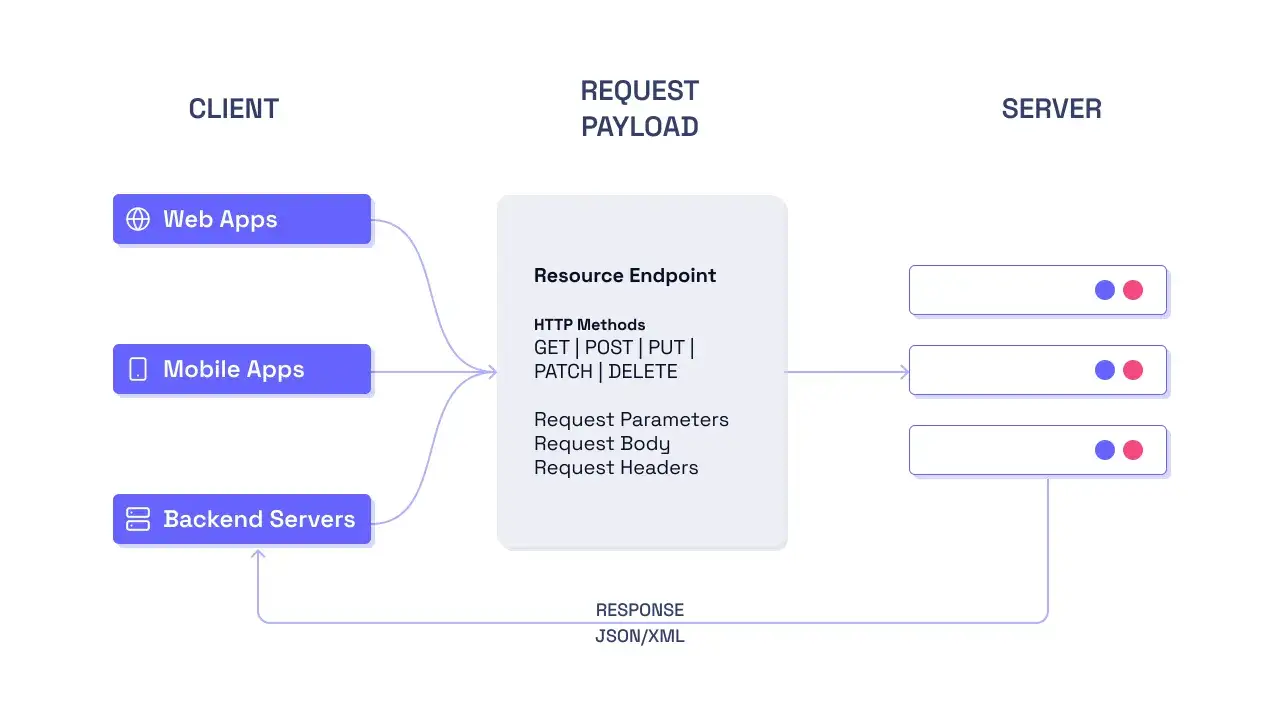
Jak operacje CRUD łączą się z HTTP i REST
Najpopularniejsze mapowanie jest dość proste: tworzenie zwykle idzie przez POST, odczyt przez GET, aktualizacja przez PUT albo PATCH, a usuwanie przez DELETE. To nie jest jednak sztywny nakaz, tylko praktyka wynikająca z semantyki HTTP. GET ma być bezpieczny i nie powinien zmieniać stanu po stronie serwera, PUT jest idempotentny i zwykle zastępuje całą reprezentację zasobu, PATCH służy do częściowej zmiany, a DELETE usuwa wskazany zasób.
| Operacja | Typowa metoda HTTP | Co robi w praktyce | Najczęstszy kod odpowiedzi |
|---|---|---|---|
| Create | POST | Dodaje nowy zasób lub wpis | 201 Created |
| Read | GET | Pobiera listę albo pojedynczy rekord | 200 OK |
| Update | PUT / PATCH | Zmienia cały zasób albo jego fragment | 200 OK / 204 No Content |
| Delete | DELETE | Usuwa zasób lub oznacza go jako usunięty | 204 No Content |
Ta tabela wygląda banalnie, ale w praktyce oszczędza sporo chaosu. Jeśli PUT zastępuje cały obiekt, to wysłanie tylko połowy pól może przypadkiem wyczyścić resztę. Jeśli PATCH służy do fragmentarycznej zmiany, trzeba jasno określić, które pola wolno edytować i jak system reaguje na brakujące dane. Przy tworzeniu zasobu dobrze sprawdza się 201 Created, bo komunikuje, że coś faktycznie powstało; przy usunięciu 204 No Content jest naturalne, bo nie zawsze trzeba odsyłać ciało odpowiedzi.
W tym miejscu często przypominam też, że CRUD nie jest tym samym co REST. CRUD opisuje operacje na danych, a REST jest stylem architektury API. Można zbudować API oparte na CRUD, ale da się też stworzyć system REST-owy z dodatkowymi akcjami domenowymi, które nie mieszczą się w czterech podstawowych czasownikach. Na poziomie protokołu wygląda to schludnie, ale w backendzie szybko pojawiają się decyzje o strukturze kodu i danych.
Jak wygląda CRUD w backendzie i bazie danych
W dobrze poukładanym projekcie każda warstwa robi swoją część roboty. Kontroler odbiera żądanie HTTP, serwis sprawdza reguły biznesowe, repozytorium wykonuje operację na danych, a baza zapisuje stan. Dzięki temu logika nie rozsypuje się po całym kodzie, tylko ma wyraźne granice. Ja zwykle zaczynam od bardzo prostego modelu zasobu, a dopiero później dokładam walidację, autoryzację i obsługę konfliktów.
POST /tasks
GET /tasks/42
PATCH /tasks/42
DELETE /tasks/42INSERT INTO tasks (title, status) VALUES ('Napisać artykuł', 'new');
SELECT * FROM tasks WHERE id = 42;
UPDATE tasks SET status = 'done' WHERE id = 42;
DELETE FROM tasks WHERE id = 42;Ten sam wzorzec działa zarówno w klasycznym SQL, jak i przy ORM-ach, tylko poziom abstrakcji jest inny. ORM ukrywa składnię zapytań, ale nie usuwa problemów projektowych: nadal musisz zdecydować, czy aktualizujesz cały obiekt, czy tylko pole, czy kasujesz rekord fizycznie, czy oznaczasz go flagą, i co zrobić, jeśli ktoś edytuje ten sam wpis równolegle. W praktyce to właśnie spójność danych odróżnia profesjonalny CRUD od „działa na moim komputerze”.
Przy tworzeniu warto pilnować kilku rzeczy: zwróć 201, jeśli zasób został utworzony; przy odczycie odróżnij brak danych od błędu serwera; przy aktualizacji miej jasną politykę walidacji; przy usuwaniu zdecyduj, czy kasujesz rekord, czy tylko go ukrywasz. Gdy pojawiają się konflikty, przydaje się wersjonowanie rekordu albo mechanizm optimistic locking, czyli sprawdzanie, czy nikt nie zmienił danych od czasu ich pobrania. To prowadzi wprost do pytań o typowe pułapki.
Najczęstsze błędy przy projektowaniu operacji na danych
W CRUD najłatwiej nie o brak funkcji, tylko o źle ustawione oczekiwania. Najczęstszy błąd to traktowanie wszystkich aktualizacji jak pełnego zastąpienia zasobu. Wtedy jeden niepełny request potrafi wyczyścić pola, których użytkownik nawet nie widział. Drugi klasyk to używanie DELETE tam, gdzie potrzebujesz audytu, historii albo możliwości odtworzenia danych. Trzeci problem pojawia się wtedy, gdy endpointy istnieją, ale nie ma na nich kontroli dostępu - wtedy każdy, kto „widzi” formularz, może także zmienić rekord, którego nie powinien.
- Mylenie PUT z PATCH - PUT traktuj jak pełną reprezentację zasobu, PATCH jak zmianę fragmentu.
- Za szybkie kasowanie danych - w systemach z historią i audytem lepiej działa soft delete.
- Brak ochrony przed nadpisaniem - dwa równoległe zapisy bez wersjonowania kończą się utratą zmian.
- Zbyt ogólne błędy - 404, 409 i 422 znaczą coś innego i warto je rozróżniać.
- Trzymanie logiki w kontrolerze - wtedy kod szybko robi się trudny do testowania i utrzymania.
Do tego dochodzi jeszcze jeden praktyczny szczegół: jeśli API jest konsumowane przez przeglądarki, boty albo integracje, to semantyka metod HTTP ma znaczenie. GET nie powinien usuwać danych, bo automatyczne indeksowanie albo prefetching potrafi wywołać efekt uboczny, którego nikt nie planował. Kiedy te zasady są jasno ustawione, łatwiej zobaczyć, gdzie CRUD wystarcza, a gdzie trzeba wyjść poza niego.
Kiedy zwykły CRUD to za mało
W prostych aplikacjach CRUD bywa pełnym opisem systemu. W produktach, które żyją dłużej, to się zmienia. Pojawiają się procesy typu „zatwierdź zamówienie”, „opłać subskrypcję”, „zamknij zgłoszenie” albo „przenieś użytkownika do innej organizacji”. To są już operacje biznesowe, a nie zwykłe edycje rekordu. Jeśli wrzucisz je na siłę do jednego uniwersalnego endpointu update, kod będzie działał, ale jego znaczenie stanie się mgliste.
| Model | Co opisuje | Gdzie działa najlepiej | Ryzyko, gdy nadużywasz |
|---|---|---|---|
| CRUD | Podstawowe operacje na zasobie | Formularze, panele administracyjne, katalogi | Zbyt uboga semantyka dla złożonych procesów |
| Operacja biznesowa | Konkretną akcję domenową | Płatności, akceptacje, workflow, zamówienia | Można przesadzić z liczbą specjalnych endpointów |
W większych systemach często rozdziela się też odczyt i zapis, chociażby w podejściu CQRS. Mówiąc prosto: to samo „czytanie danych” i „modyfikowanie danych” nie zawsze potrzebuje tej samej struktury. Lista w panelu, raport, wyszukiwarka i formularz edycji mogą korzystać z innych modeli danych, bo mają inne cele i inne wymagania wydajnościowe. To nie jest obowiązek, ale bywa bardzo rozsądne, gdy aplikacja rośnie i zwykły CRUD zaczyna być zbyt ciasny.
Ja patrzę na to tak: CRUD daje dobry szkielet, ale nie powinien udawać całej domeny. Jeśli operacja ma znaczenie biznesowe, nazwij ją po biznesowemu; jeśli to po prostu zapis pola w rekordzie, nie komplikuj jej sztucznie. Takie rozróżnienie oszczędza zespołowi sporów, a użytkownikowi daje bardziej przewidywalne zachowanie systemu.
Co zostaje z CRUD, gdy projekt dojrzewa
Najbardziej użyteczna lekcja jest prosta: CRUD to fundament, nie ograniczenie. Jeśli projektujesz mały panel, system CMS albo prostą aplikację do zarządzania danymi, ten model pozwala szybko dojść do porządku. Jeśli budujesz większy produkt, CRUD nadal zostaje w środku, ale obok niego pojawiają się reguły biznesowe, wersjonowanie, autoryzacja, soft delete, statusy odpowiedzi i operacje domenowe, które lepiej opisują realne zachowanie systemu.
Gdybym miał zostawić jedną praktyczną zasadę, brzmiałaby tak: najpierw porządnie nazwij zasób i jego cztery podstawowe operacje, a dopiero potem dokładaj wszystko, co wynika z logiki biznesowej. To daje czytelniejszy kod, prostsze API i mniej nieporozumień w zespole. Dobrze zrobiony CRUD nie jest celem samym w sobie, tylko solidną bazą pod system, który da się rozwijać bez bólu.