
Szyfrowanie połączeń to dziś podstawowy element ochrony danych w sieci. TLS zabezpiecza transmisję między przeglądarką, aplikacją i serwerem, ale samo jego włączenie nie wystarcza, jeśli konfiguracja jest słaba albo certyfikaty żyją własnym życiem. W tym tekście rozkładam na czynniki pierwsze, jak działa ten mechanizm, które wersje mają sens w 2026 roku i na co zwrócić uwagę, żeby bezpieczeństwo nie było tylko pozorne.
Najważniejsze fakty o bezpiecznym kanale w sieci
- Protokół chroni ruch w tranzycie przez szyfrowanie, uwierzytelnianie serwera i kontrolę integralności danych.
- W 2026 roku najlepszym wyborem jest TLS 1.3, a 1.2 zostaje głównie jako warstwa kompatybilności.
- Wersje 1.0 i 1.1 są przestarzałe i w praktyce nie powinny być utrzymywane na nowych usługach.
- Sam protokół nie naprawi błędów aplikacji, przejętego serwera ani złośliwego oprogramowania po stronie użytkownika.
- Równie ważne jak szyfrowanie są: poprawny certyfikat, rotacja kluczy, HSTS i rozsądna polityka wersji.
- W API i komunikacji wewnętrznej coraz częściej przydaje się też mTLS, czyli uwierzytelnianie obu stron.
Czym jest TLS i dlaczego nadal jest filarem bezpieczeństwa
Najprościej mówiąc, TLS to warstwa, która zamyka komunikację w bezpiecznym kanale. Jeśli widzisz HTTPS, to właśnie ten protokół pracuje pod spodem i pilnuje, żeby nikt po drodze nie podejrzał treści ani jej nie podmienił. Ja traktuję go nie jak „dodatek do strony”, ale jak podstawowy mechanizm zaufania między klientem a serwerem.
To, co kiedyś nazywano SSL, dziś jest w praktyce historią technologiczną. W codziennej pracy nie chodzi już o nostalgiczne nazewnictwo, tylko o to, czy połączenie jest rzeczywiście odporne na podsłuch, manipulację i podszywanie się pod usługę. Właśnie dlatego ten protokół jest tak ważny nie tylko w przeglądarce, ale też w API, poczcie, aplikacjach mobilnych i komunikacji między usługami.
Warto też odróżnić sam protokół od certyfikatu. Certyfikat nie szyfruje danych sam z siebie, tylko potwierdza tożsamość serwera i pomaga uzgodnić klucze sesyjne. Jeśli rozumiesz tę różnicę, dużo łatwiej ocenisz, czy dana konfiguracja naprawdę podnosi poziom ochrony, czy tylko „świeci kłódką”. A skoro to mamy jasne, czas zobaczyć, co dokładnie jest chronione, a czego ten mechanizm nie załatwia.
Co zabezpiecza w komunikacji, a czego nie rozwiązuje
Największa wartość TLS polega na tym, że chroni ruch w trakcie przesyłania. To ważne, bo większość realnych ataków na słabą komunikację nie polega na łamaniu algorytmu szyfrowania, tylko na podsłuchu, podmianie danych albo przechwyceniu sesji w miejscu, gdzie ktoś liczył na „zwykły HTTP”.
| Chroni | Nie chroni |
|---|---|
| Podsłuchem treści w trakcie transmisji | Przejętym laptopem, telefonem lub serwerem |
| Podmianą danych po drodze | Błędami logiki aplikacji i lukami w autoryzacji |
| Uwierzytelnieniem serwera dla klienta | Phishingiem, jeśli użytkownik trafi na inną domenę |
| Integralnością przesyłanych pakietów | Wyciekiem danych z bazy lub kopii zapasowej |
W praktyce to oznacza jedną rzecz: nawet idealnie skonfigurowany kanał nie zastąpi dobrego uwierzytelniania użytkowników, kontroli dostępu i bezpieczeństwa po stronie aplikacji. Jeśli przetwarzasz dane osobowe albo płatności, TLS jest absolutnym minimum technicznym, ale sam w sobie nie daje zgodności z żadnym standardem czy regulacją. Dopiero razem z resztą mechanizmów tworzy sensowną ochronę.
Żeby dobrze dobrać ustawienia, trzeba jeszcze zobaczyć, jak wygląda samo uzgadnianie połączenia. To właśnie tam rozstrzyga się, czy komunikacja będzie szybka, stabilna i rzeczywiście bezpieczna.
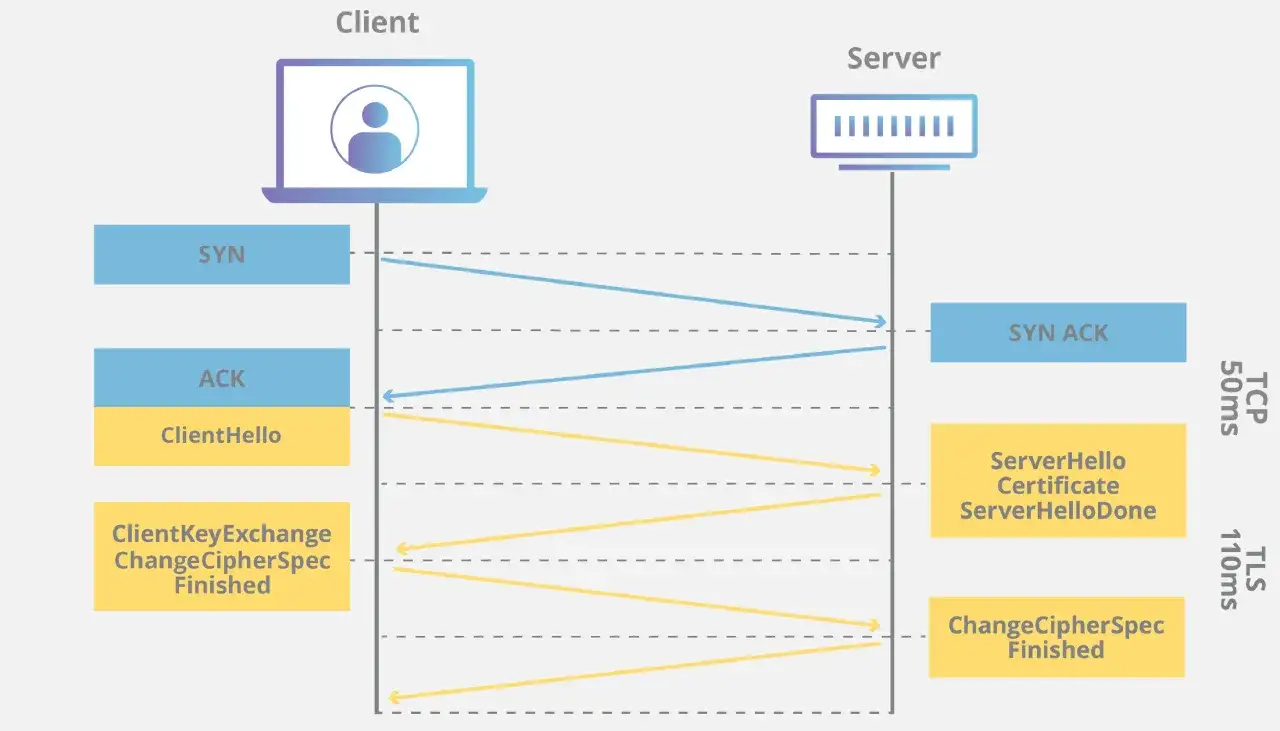
Jak przebiega uzgadnianie połączenia krok po kroku
Handshake to moment, w którym klient i serwer ustalają zasady gry. Najpierw negocjują parametry, potem weryfikują tożsamość i na końcu przechodzą na szyfrowanie symetryczne, które jest szybsze w codziennej transmisji. To właśnie dlatego TLS łączy dwa światy: kryptografię asymetryczną na start i symetryczną w dalszej rozmowie.
- Klient wysyła ClientHello z obsługiwanymi wersjami, zestawami szyfrów i parametrami wymiany kluczy.
- Serwer odpowiada ServerHello, wybierając konkretny zestaw ustawień i przedstawiając certyfikat.
- Klient sprawdza certyfikat, czyli czy domena, łańcuch zaufania i podpisy są poprawne.
- Obie strony uzgadniają klucz sesyjny i od tego momentu szyfrują ruch już kanałem symetrycznym.
- Na końcu komunikacja Finished potwierdza, że nikt nie wtrącił się po drodze.
Pełne uzgadnianie
W pełnym połączeniu obie strony przechodzą przez cały proces od zera. W TLS 1.3 zwykle zamyka się to w jednym RTT, czyli jednym pełnym obiegu sieciowym. To realnie zmniejsza opóźnienie, zwłaszcza tam, gdzie użytkownik łączy się przez wolniejsze albo bardziej kapryśne sieci.
Przeczytaj również: Jak podłączyć domofon Laskomex - uniknij błędów i problemów z instalacją
Wznowienie sesji i 0-RTT
Jeśli klient łączy się ponownie, można wykorzystać wznowienie sesji. W 1.3 dochodzi też opcja 0-RTT, czyli wysłania części danych bez czekania na pełny obieg. Brzmi świetnie, ale ma haczyk: dane wczesne mogą być podatne na ataki typu replay, więc nadają się głównie do żądań bezpiecznych z punktu widzenia powtórzenia, a nie do wszystkiego, co przychodzi do głowy.
Właśnie dlatego protokół jest jednocześnie szybki i ostrożny. A skoro już wiemy, jak działa od środka, czas odpowiedzieć na pytanie, którą wersję i jakie ustawienia naprawdę warto dziś zostawić włączone.
Którą wersję warto ustawić w 2026 roku
Tu nie ma wielkiej zagadki: w 2026 roku preferuję TLS 1.3, a 1.2 zostawiam tylko tam, gdzie kompatybilność nadal ma sens. Wersje 1.0 i 1.1 nie powinny być domyślnym wyborem na żadnej nowej usłudze, bo ich koszt bezpieczeństwa jest po prostu zbyt wysoki.
| Wersja | Status w 2026 | Co daje | Kiedy zostawić |
|---|---|---|---|
| 1.3 | Rekomendowana | Szybszy handshake, prostsza konfiguracja, mniej starych pułapek | Prawie zawsze, jako domyślna opcja |
| 1.2 | Akceptowalna jako fallback | Dobra zgodność z starszymi klientami | Gdy masz realnych użytkowników lub urządzenia bez 1.3 |
| 1.1 | Przestarzała | Brak przewagi nad nowszymi wersjami | Wyłącznie krótkoterminowo, jeśli nie ma wyjścia |
| 1.0 | Do wycofania | Kompatybilność ze starym sprzętem | Tylko w bardzo specyficznych środowiskach legacy |
Różnica nie dotyczy wyłącznie szybkości. TLS 1.3 uprościł cały model negocjacji, usunął część historycznego balastu i mocniej opiera się na nowoczesnych konstrukcjach kryptograficznych. Z punktu widzenia administratora to dobra wiadomość, bo jest mniej miejsc, w których da się przypadkiem otworzyć dziurę.
Jeśli masz starsze integracje, nie warto od razu wycinać wszystkiego bez testów. Urządzenia przemysłowe, starsze biblioteki lub zamknięte systemy B2B czasem nadal potrzebują 1.2. Wtedy rozsądne jest podejście etapowe: 1.3 jako domyślny wybór, 1.2 jako kontrolowany kompromis, a stare wersje tylko tam, gdzie naprawdę nie da się ich jeszcze odciąć. Ta różnica ma sens tylko wtedy, gdy wybór pasuje do klientów i urządzeń, z którymi się łączysz.
Gdzie TLS jest potrzebny poza stroną WWW
Najczęściej mówi się o HTTPS, ale ja patrzę szerzej. Ten protokół jest równie ważny w API, aplikacjach mobilnych, poczcie, panelach administracyjnych i komunikacji między mikrousługami. Tam, gdzie dane naprawdę mają wartość, zwykły „wewnętrzny ruch w sieci firmowej” nie jest żadnym argumentem za rezygnacją z szyfrowania.
- API publiczne - chroni tokeny, dane klientów i odpowiedzi serwera przed podsłuchem po drodze.
- Aplikacje mobilne - zabezpiecza ruch w niestabilnych sieciach Wi-Fi i sieciach komórkowych.
- Poczta i usługi synchroniczne - ogranicza ryzyko przechwycenia logowań oraz treści wiadomości.
- Komunikacja serwis-serwis - utrzymuje zaufanie między komponentami bez wystawiania ich na otwarty Internet.
W tym obszarze coraz częściej przydaje się mTLS, czyli wzajemne uwierzytelnianie certyfikatami po obu stronach. To bardzo sensowne rozwiązanie w środowiskach zero trust, w service mesh i w API B2B, gdzie nie wystarczy już tylko sprawdzić serwer. Ja lubię je tam, gdzie chcę powiedzieć jasno: nie tylko klient ma ufać serwerowi, ale serwer też musi wiedzieć, kto do niego mówi.
Jednocześnie mTLS nie jest darmowe operacyjnie. Trzeba zarządzać certyfikatami po obu stronach, rotacją, odwołaniem i onboardingiem nowych usług. Dlatego w publicznym webie bywa overkill, ale w środowisku produkcyjnym o wysokiej poufności potrafi być bardzo trafiony. I właśnie tu najłatwiej popełnić błędy, które psują nawet dobrą bazę kryptograficzną.
Najczęstsze błędy, które psują nawet dobry protokół
W praktyce najwięcej problemów nie robi sam protokół, tylko jego wdrożenie. Widzę to często: ktoś chwali się szyfrowaniem, a obok stoi przestarzały certyfikat, mieszana zawartość HTTP i HTTPS albo obsługa starych wersji „na wszelki wypadek”. To nie są drobiazgi. To są miejsca, w których bezpieczeństwo zaczyna się sypać.
- Przeterminowany certyfikat - po prostu zabija zaufanie użytkownika i potrafi odciąć dostęp do usługi.
- Brak pełnego łańcucha zaufania - przeglądarka lub klient API nie potwierdza tożsamości serwera tak, jak powinien.
- Mieszana zawartość - strona ładuje część zasobów po HTTP i przez to rozmywa sens całej ochrony.
- Zbyt szeroka kompatybilność - utrzymywanie 1.0 lub 1.1 bez realnej potrzeby podnosi ryzyko bez zysku.
- Brak HSTS - użytkownik nadal może zostać sprowadzony do niebezpiecznego wejścia w HTTP.
- Nieuważne użycie 0-RTT - powtórzone żądania mogą przynieść więcej szkody niż korzyści.
- Brak rotacji i monitoringu - wszystko działa, dopóki nagle nie przestaje działać w najgorszym możliwym momencie.
Jeśli miałbym wskazać jeden praktyczny błąd, który pojawia się najczęściej, to powiedziałbym: „szyfrowanie włączone, ale cała reszta zostawiona przypadkowi”. Sama kłódka nie wystarczy, gdy certyfikat wygasa bez nadzoru albo proxy po drodze łamie łańcuch zaufania. To właśnie dlatego przed wdrożeniem warto mieć prostą, twardą checklistę.
Na koniec zostaje już tylko kontrola wdrożenia i monitoring zmian. To właśnie tam oddziela się konfigurację „na papierze” od konfiguracji, która naprawdę działa w produkcji.
Co sprawdziłbym przed wdrożeniem i po każdej zmianie
Gdy przygotowuję usługę do produkcji, zaczynam od podstaw. Najpierw sprawdzam wersje protokołu, potem certyfikat, następnie łańcuch zaufania, a dopiero na końcu detale typu zestawy szyfrów czy HSTS. To prosta kolejność, ale oszczędza sporo czasu, bo najpierw usuwa problemy krytyczne, a dopiero potem dopracowuje szczegóły.
- Czy certyfikat jest ważny, poprawnie przypisany do domeny i ma pełny łańcuch.
- Czy minimum to 1.2, a preferencja idzie na 1.3.
- Czy aplikacja nie ładuje zasobów po HTTP.
- Czy przekierowanie z HTTP na HTTPS działa bez pętli i bez wyjątków.
- Czy HSTS jest ustawiony rozsądnie, a nie „na ślepo” na zbyt długi czas.
- Czy logi i alerty pokazują błędy handshake, problemy z certyfikatem i spadki zgodności po odnowieniu.
- Czy testy po wdrożeniu przechodzą zarówno w przeglądarce, jak i w narzędziach typu
curllubopenssl s_client.
W praktyce lubię też porównać wynik przed i po zmianie, zamiast zakładać, że „na pewno jest lepiej”. Jeden źle ustawiony load balancer potrafi zepsuć wszystko, nawet jeśli backend ma poprawną konfigurację. Dlatego dobrze ustawiony transport nie jest dodatkiem do bezpieczeństwa produktu, tylko jego częścią; jeśli tu zrobi się dobrze, cała reszta ma znacznie solidniejszy grunt pod nogami.