
Ochrona danych przed odczytem przez osoby nieuprawnione to nie ozdobnik techniczny, tylko fundament bezpieczeństwa w firmach i na prywatnych urządzeniach. Dobrze wdrożone szyfrowanie zmniejsza skutki kradzieży laptopa, przechwycenia ruchu sieciowego czy wycieku kopii zapasowej, ale samo w sobie nie załatwia wszystkiego. Ja patrzę na ten temat praktycznie: liczy się nie tylko algorytm, ale też klucze, procedury odzyskiwania i to, gdzie dane mogą zostać przechwycone.
Najkrócej: bezpieczeństwo danych zależy bardziej od kluczy niż od samego algorytmu
- Najczęściej stosuje się trzy podejścia: symetryczne, asymetryczne i hybrydowe.
- Wydajność ma znaczenie przy dyskach i kopiach zapasowych, a wymiana kluczy przy komunikacji sieciowej.
- Największym ryzykiem zwykle nie jest sam algorytm, tylko złe zarządzanie kluczami i wyjątkami w systemie.
- W praktyce trzeba chronić zarówno dane zapisane, jak i dane przesyłane między systemami.
- W 2026 roku warto myśleć także o długim cyklu życia danych i o migracji do nowych standardów odporności.
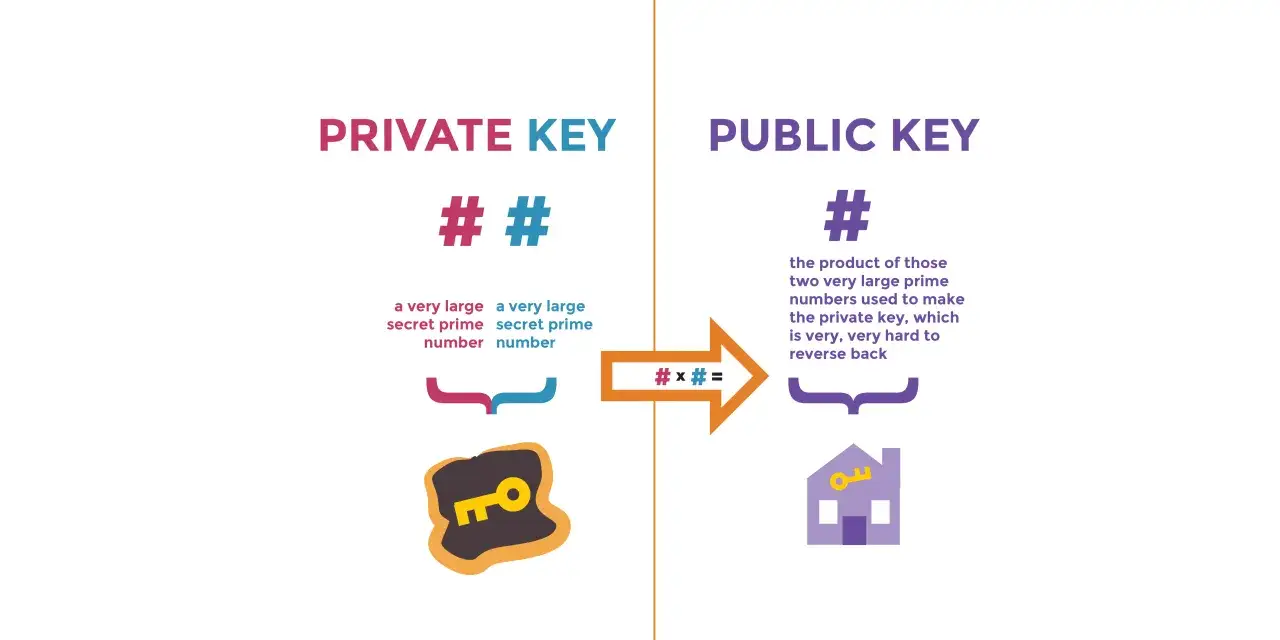
Jak działa szyfrowanie danych
Mechanizm jest prosty w założeniu: czytelna informacja trafia do algorytmu razem z kluczem, a wynik staje się bezużyteczny dla kogoś, kto klucza nie zna. Dopiero po podaniu właściwego klucza można odzyskać pierwotną treść. To właśnie dlatego bezpieczeństwo zależy bardziej od klucza i wdrożenia niż od samej nazwy algorytmu.
W praktyce spotykam dwa podstawowe modele. W wariancie symetrycznym ten sam klucz służy do zabezpieczania i odczytu danych, więc rozwiązanie jest szybkie i świetnie sprawdza się przy dużych plikach, dyskach czy archiwach. W wariancie asymetrycznym działa para kluczy: publiczny do zabezpieczania i prywatny do odczytu, co ułatwia wymianę danych w sieci i budowę zaufania między stronami.
Najważniejszy wniosek jest taki, że sama matematyka nie wystarcza. Jeśli klucz leży obok danych, jeśli jest słaby albo jeśli system źle obsługuje wyjątki, cała warstwa ochronna traci sens. To prowadzi do pytania, jakie podejścia warto odróżniać w praktyce, zamiast wrzucać wszystko do jednego worka.
Jakie podejścia spotyka się najczęściej
W realnych systemach rzadko wybiera się jeden mechanizm do wszystkiego. Najlepsze wdrożenia zwykle łączą kilka warstw, bo inne wymagania ma dysk laptopa, inne bankowość internetowa, a jeszcze inne komunikator firmowy.
| Metoda | Do czego służy | Największa zaleta | Ograniczenie | Kiedy ma sens |
|---|---|---|---|---|
| Symetryczna | Dyski, backupy, duże zbiory danych | Bardzo dobra wydajność | Trudniejsze bezpieczne przekazanie klucza | Gdy liczy się szybkość i skala |
| Asymetryczna | Wymiana kluczy, podpisy, tożsamość | Łatwiejsze zaufanie między stronami | Jest wolniejsza i cięższa obliczeniowo | Gdy potrzebujesz bezpieczeństwa komunikacji |
| Hybrydowa | Nowoczesne protokoły internetowe | Łączy zalety dwóch poprzednich podejść | Wymaga dobrej implementacji po obu stronach | Gdy system ma działać szybko i bezpiecznie jednocześnie |
| Model end-to-end | Komunikatory i wybrane systemy współpracy | Odczyt możliwy tylko na końcach komunikacji | Nie chroni wszystkiego, zwłaszcza metadanych i kompromitacji urządzenia | Gdy prywatność rozmów ma pierwszeństwo |
Haszowanie to coś innego. Nie służy do odzyskiwania treści, tylko do sprawdzania integralności albo do bezpiecznego przechowywania haseł w formie nieodwracalnej. To częste źródło pomyłek, zwłaszcza w zespołach, które wdrażają bezpieczeństwo „na szybko”.
Sama technika nie wygrywa jednak wszystkich scenariuszy. Trzeba jeszcze wiedzieć, gdzie chronić dane najmocniej i jakie zagrożenie jest w danym przypadku najbardziej realne.
Gdzie ochrona kryptograficzna daje najwięcej
Największą różnicę widzę w czterech miejscach: na urządzeniach końcowych, w transmisji sieciowej, w kopiach zapasowych i w systemach przechowujących dane osobowe. Jeśli zniknie laptop, nośnik z kopią albo zewnętrzny dysk, dobrze zabezpieczone dane nie zamieniają się automatycznie w otwarty plik. W praktyce to właśnie tam ochrona daje najszybszy i najbardziej namacalny efekt.
- Laptopy i dyski - chronią przed skutkami kradzieży, zgubienia albo fizycznego dostępu do sprzętu.
- Backupy - zabezpieczają archiwa, które często są mniej pilnowane niż produkcyjne bazy.
- API i ruch między usługami - ograniczają przechwycenie danych w drodze między systemami.
- Komunikatory i poczta - mają znaczenie tam, gdzie poufność treści jest ważniejsza niż sama wygoda.
Jak dobrać rozwiązanie do realnego ryzyka
Ja zwykle zaczynam od prostego pytania: czy chronię dane zapisane, dane przesyłane, czy oba przypadki naraz? Dopiero potem wybieram narzędzia. W większości organizacji najlepiej działa układ warstwowy, a nie jedno „magiczne” rozwiązanie.
- Najpierw klasyfikuję dane według wrażliwości i czasu życia. Krótkotrwały dokument roboczy wymaga innego podejścia niż archiwum medyczne albo dane finansowe.
- Potem zabezpieczam nośniki i kopie zapasowe. W praktyce często wybiera się AES-256, bo dobrze radzi sobie z dużą ilością danych i jest standardem, który daje solidny zapas bezpieczeństwa.
- Następnie ustawiam ochronę transmisji między systemami. Tu liczy się nie tylko sam protokół, ale też poprawna konfiguracja serwera, certyfikatów i bibliotek po stronie aplikacji.
- Na końcu oddzielam klucze od danych. Najlepiej, gdy klucze są przechowywane w dedykowanej usłudze albo module bezpieczeństwa, a nie w tym samym miejscu co zasoby, które mają chronić.
- Na koniec testuję odzyskiwanie. Ochrona, której nie da się przywrócić po awarii, jest tylko częściowo użyteczna.
W praktyce oznacza to, że nawet dobre narzędzie może zawieść, jeśli ktoś uprości wdrożenie albo pominie procedury operacyjne. Dla wielu firm najrozsądniejszy jest standard, który da się utrzymać codziennie, zamiast ambitnej konfiguracji, której nikt nie rozumie po trzech miesiącach. Kiedy ta warstwa działa, od razu widać też błędy, które najczęściej psują cały efekt.
Najczęstsze błędy, które rozbrajają ochronę
Najczęściej nie przegrywa się z matematyką, tylko z organizacją. Widziałem systemy, w których algorytm był poprawny, a mimo to całość była słaba, bo klucze leżały obok danych, backupy nie były chronione, a zespoły korzystały z przestarzałych bibliotek.
- Trzymanie kluczy w tym samym środowisku co dane - to klasyczny błąd, bo atakujący po wejściu do jednego miejsca dostaje też dostęp do drugiego.
- Własne, „autorskie” rozwiązania - kryptografia zrobiona bez standardów i bez audytu zwykle kończy się źle.
- Mylenie pojęć - hashowanie, podpis cyfrowy i ochrona poufności rozwiązują różne problemy.
- Pomijanie kopii zapasowych - dobrze zabezpieczona produkcja nie pomaga, jeśli backup jest otwarty dla wszystkich.
- Stare biblioteki i stare protokoły - nawet poprawny projekt może zostać osłabiony przez nieaktualną implementację.
- Zbyt słabe hasła do systemów zarządzających kluczami - technologia nie nadrabia słabej higieny dostępu.
Właśnie dlatego lubię patrzeć na bezpieczeństwo jako na łańcuch, a nie pojedynczy element. Jeśli jeden ogniwo jest miękkie, cała konstrukcja zaczyna przeciekać. A dziś dochodzi do tego jeszcze jeden temat: odporność na przyszłe ataki i planowanie migracji zanim zrobi się pilnie.
Dlaczego w 2026 roku warto myśleć o postkwantowej migracji
NIST już opublikował pierwsze standardy postkwantowe, więc temat nie jest już akademicką ciekawostką, tylko realnym kierunkiem zmian w branży. Nie oznacza to, że trzeba natychmiast przepisywać wszystkie systemy. Oznacza raczej, że dla danych o długim czasie poufności warto już dziś projektować kryptograficzną zwinność, czyli możliwość wymiany algorytmów bez przebudowy całego stosu.
To ważne zwłaszcza tam, gdzie informacja ma wartość przez wiele lat: w archiwach, dokumentacji medycznej, sektorze publicznym, finansach czy w systemach przemysłowych. Model „zabezpiecz dziś, odszyfruj później” jest realnym ryzykiem dla danych przechwyconych teraz, ale wciąż cennych za kilka lat. Jeśli materiał ma długi okres poufności, jego zabezpieczenie powinno być myślane długoterminowo, nie tylko pod dzisiejsze zagrożenia.
To nie jest powód do paniki. To jest powód, żeby projektować systemy tak, aby dało się w nich wymienić algorytm, odświeżyć certyfikaty i przejść na nowe standardy bez chaosu operacyjnego. Jeśli nie budujesz archiwum na dekady, nie musisz robić wszystkiego naraz, ale plan migracji warto mieć wcześniej niż później.
Od czego zacząć, żeby ta warstwa naprawdę działała
Jeśli miałbym wskazać jeden sensowny porządek działania, zacząłbym od danych, potem zajął się nośnikami i transmisją, a dopiero na końcu dopracował bardziej zaawansowane elementy. Najpierw zabezpieczam laptopy, backupy i kanały komunikacji. Potem oddzielam klucze od danych, ustalam procedury odzyskiwania i sprawdzam, czy cały proces da się odtworzyć po awarii albo utracie dostępu.
Dobrze ustawiona warstwa kryptograficzna nie jest widowiskowa, ale po incydencie robi ogromną różnicę. W praktyce właśnie ona często decyduje, czy wyciek staje się kryzysem, czy tylko incydentem, który da się zamknąć bez większych strat.