
Centrum operacji bezpieczeństwa to miejsce, w którym sygnały z sieci, chmury, endpointów i aplikacji zamieniają się w decyzje: ignorować, eskalować, odciąć dostęp albo rozpocząć odtwarzanie usług. W praktyce właśnie tutaj widać, czy firma naprawdę panuje nad ryzykiem, czy tylko zbiera alerty z kilku narzędzi i liczy, że problem sam minie. Poniżej rozkładam ten temat na części: od definicji i działania, przez narzędzia i modele wdrożenia, aż po błędy, które najczęściej psują cały efekt.
Najważniejsze rzeczy o centrum operacji bezpieczeństwa
- W bezpieczeństwie skrót SOC oznacza Security Operations Center, czyli zespół, procesy i narzędzia do wykrywania oraz reagowania na incydenty.
- Nie warto mylić go z SoC, czyli System on a Chip, który dotyczy elektroniki i hardware’u.
- Dobrze działający SOC pracuje 24/7, bo ataki nie pojawiają się wyłącznie w godzinach pracy.
- Najważniejsze elementy to monitoring, korelacja logów, triage alertów, playbooki reakcji i możliwość szybkiej eskalacji.
- W wielu firmach największą różnicę robi nie samo narzędzie, lecz jakość procesu i jasne uprawnienia do działania.
- Model usługowy bywa rozsądniejszy niż własny SOC, jeśli organizacja nie ma budżetu i ludzi do obsady zmian.
Czym jest SOC i z czym najczęściej się go myli
W obszarze bezpieczeństwa SOC to nie pojedynczy produkt, tylko centrum operacji bezpieczeństwa: połączenie ludzi, procedur i technologii, które mają jeden cel, czyli szybciej wykrywać zagrożenia i skuteczniej na nie reagować. To właśnie dlatego tak często myli się go z SIEM-em, który jest tylko jedną z technologicznych warstw, albo z CSIRT-em, który zwykle kojarzy się bardziej z reagowaniem na incydenty niż z codziennym monitoringiem. I jeszcze jedna ważna rzecz: w elektronice podobnie zapisany skrót SoC oznacza System on a Chip, więc w rozmowie zakupowej czy projektowej naprawdę łatwo o nieporozumienie.
Najprościej myślę o SOC jak o „mózgu operacyjnym” bezpieczeństwa. Jeśli SIEM zbiera i koreluje logi, EDR widzi zachowanie endpointów, a SOAR automatyzuje część reakcji, to SOC spina to w logiczny proces decyzyjny. Bez tego narzędzia mogą działać poprawnie, a mimo to organizacja dalej będzie wolna, chaotyczna i ślepa na najgroźniejsze zdarzenia.
| Pojęcie | Co oznacza | Rola w praktyce |
|---|---|---|
| SOC | Centrum operacji bezpieczeństwa | Monitoruje, analizuje i koordynuje reakcję na zagrożenia |
| SIEM | Platforma do zbierania i korelacji logów | Daje widoczność i kontekst dla alertów |
| CSIRT | Zespół reagowania na incydenty | Wchodzi mocniej do gry, gdy problem już się wydarzył |
| MDR | Zarządzana usługa wykrywania i reagowania | Przenosi część pracy operacyjnej do dostawcy |
To rozróżnienie ma znaczenie, bo od niego zależy, czego naprawdę potrzebuje organizacja. Gdy już wiemy, czym SOC jest, łatwiej przejść do tego, jak wygląda jego codzienna praca i dlaczego bez dobrego procesu samo „widzenie” niczego nie załatwia.
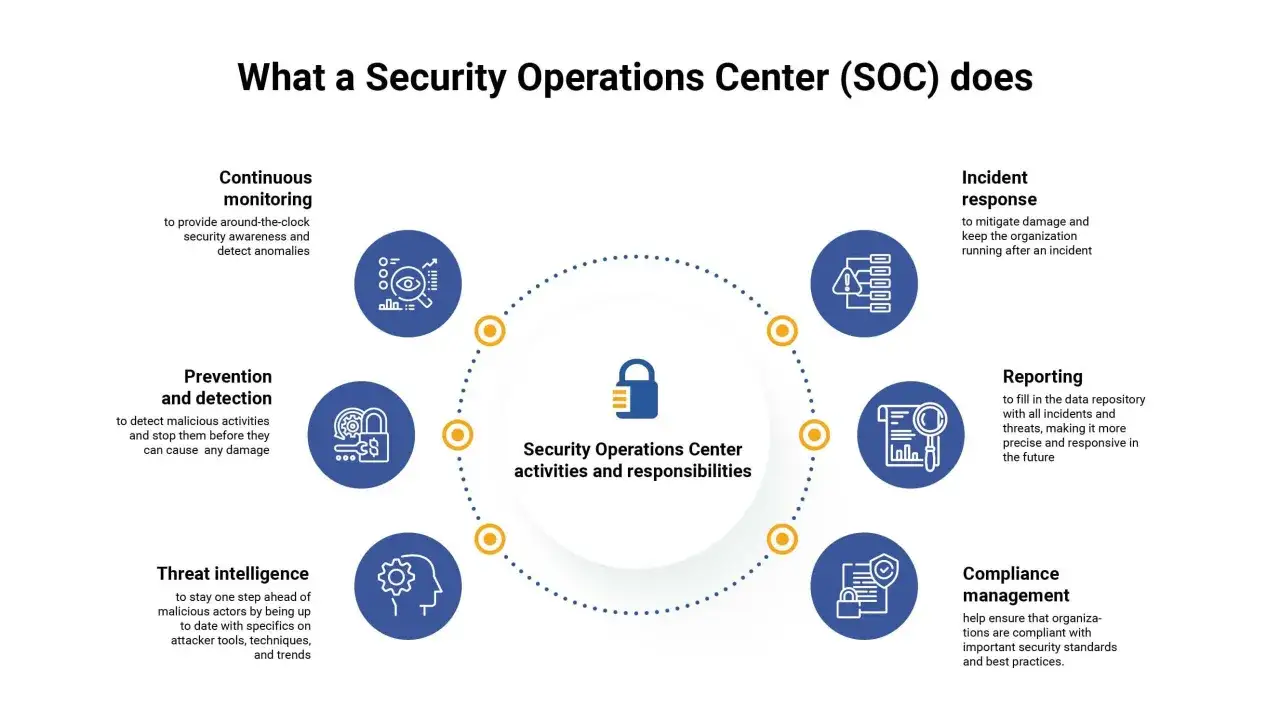
Jak SOC działa w praktyce od sygnału do reakcji
W dobrze poukładanym środowisku SOC pracuje jak filtr i przyspieszacz jednocześnie: zbiera duży wolumen zdarzeń, odrzuca szum i zostawia tylko to, co naprawdę wymaga decyzji. NIST w SP 800-61r3 opisuje ten świat jako jeden cykl obejmujący wykrywanie, reagowanie i odzyskiwanie, a nie trzy osobne projekty. To ważne, bo wiele zespołów popełnia błąd polegający na traktowaniu alertu, reakcji i naprawy jako zupełnie niezależnych zadań.
- Zbieranie telemetrii - do SOC trafiają logi z serwerów, endpointów, chmury, tożsamości, sieci, poczty i aplikacji. Im lepsze pokrycie, tym mniejsze ryzyko, że atak przejdzie bokiem.
- Korelacja i wzbogacanie - pojedynczy alert mówi mało, ale kilka sklejonych zdarzeń potrafi ujawnić pełny łańcuch ataku. Tu liczy się kontekst: kto, skąd, na jakim zasobie i w jakim czasie.
- Triage - analityk ocenia, czy to fałszywy alarm, incydent niskiego ryzyka, czy realne naruszenie. Bez dobrych reguł i progów priorytetyzacja zamienia się w zgadywanie.
- Eskalacja - gdy sprawa wykracza poza standardowy scenariusz, SOC przekazuje ją do odpowiednich osób: administratorów, zespołu IR, właściciela systemu albo zarządu, jeśli ryzyko jest biznesowe.
- Containment - celem nie jest od razu „zniszczyć wszystko”, tylko zatrzymać rozprzestrzenianie się zagrożenia, na przykład przez izolację stacji, blokadę konta lub odcięcie ruchu.
- Lessons learned - po incydencie trzeba poprawić reguły, playbooki, komunikację i zabezpieczenia, bo bez tego ten sam błąd wróci przy następnym ataku.
W 2026 największą różnicę robi szybkość tego obiegu. Jeśli SOC reaguje po godzinie, a nie po kilku minutach, firma płaci już nie tylko technicznie, ale też operacyjnie i wizerunkowo. I właśnie dlatego sam „monitoring” to za mało, co prowadzi do pytania o realne składniki takiego centrum.
Z czego składa się nowoczesny SOC
Nowoczesny SOC nie jest pokojem pełnym ekranów. To raczej ekosystem, w którym narzędzia mają wspierać decyzje, a nie tworzyć ich pozór. Gdy analizuję wdrożenia, najczęściej widzę, że sukces zależy od tego, czy organizacja zbudowała sensowny łańcuch od danych wejściowych do reakcji, zamiast kupować kolejne rozwiązania „na zapas”.
| Element | Po co jest | Co psuje dojrzałość |
|---|---|---|
| SIEM | Zbiera i koreluje logi z wielu źródeł | Brak źródeł danych, złe reguły, za dużo szumu |
| EDR/XDR | Pokazuje zachowanie endpointów i często także innych warstw | Brak wdrożenia na wszystkich urządzeniach i serwerach |
| SOAR | Automatyzuje część działań i orkiestruje reakcję | Automatyzacja bez playbooków i bez nadzoru człowieka |
| Threat intelligence | Dostarcza informacji o nowych technikach i wskaźnikach ataku | Brak selekcji, zbyt dużo nieprzetworzonych feedów |
| Case management | Porządkuje sprawy, eskalacje i dowody | Chaos w komunikacji i brak historii decyzji |
| Playbooki | Opisują, co robić przy konkretnym scenariuszu | Reakcja zależna od pamięci analityka zamiast od procesu |
| Inwentaryzacja aktywów | Pokazuje, co w ogóle chronimy | Brak pełnej wiedzy o serwerach, kontach i usługach |
Do tego dochodzi warstwa ludzka. W praktyce spotyka się analityków L1, L2 i L3, threat hunterów, osoby od reakcji na incydenty i managera SOC, który pilnuje priorytetów oraz jakości usług. Nie każda organizacja potrzebuje pełnego układu, ale każda potrzebuje jasnego właściciela decyzji. Bez tego nawet najlepsze narzędzia zostają na poziomie dekoracji.
Właśnie dlatego coraz częściej mówi się o automatyzacji, ale ja patrzę na nią ostrożnie: automatyzacja ma skracać czas reakcji, a nie zastępować zdrowy rozsądek. Jeśli następny krok ma być zakupem albo outsourcingiem, trzeba najpierw zdecydować, kto ma to wszystko utrzymywać i na jakich warunkach.
Własny SOC, usługa SOCaaS czy model hybrydowy
To jeden z tych wyborów, w których teoria bywa prosta, a praktyka już nie. CISA opisuje SOCaaS jako usługę obejmującą całodobowe monitorowanie, wykrywanie, analizę, threat intelligence, dochodzenia i reakcję na incydenty. To dobry punkt odniesienia, bo pokazuje, że przy zakupie usługi nie chodzi tylko o „ładny panel”, lecz o realną obsługę operacyjną.
| Model | Kiedy ma sens | Największa zaleta | Największy kompromis |
|---|---|---|---|
| Własny SOC | Gdy organizacja ma duży wolumen danych, wysokie wymagania i własną kulturę bezpieczeństwa | Pełna kontrola nad procesem, danymi i reakcją | Trudna rekrutacja, dyżury 24/7 i wyższy koszt utrzymania |
| SOCaaS | Gdy firma chce szybko zyskać monitoring i reakcję bez budowania wszystkiego od zera | Szybszy start i mniejszy ciężar operacyjny | Zależność od dostawcy i mniejsza elastyczność w niestandardowych procesach |
| Model hybrydowy | Gdy część kompetencji zostaje wewnątrz, a część obsługi przejmuje partner | Dobre połączenie kontroli i skali | Wymaga bardzo jasnego podziału odpowiedzialności |
W praktyce najczęściej polecałbym model hybrydowy firmom, które mają własny zespół IT, ale nie chcą samodzielnie budować nocnych i weekendowych zmian. Najdroższe rzadko bywa samo narzędzie, tylko obsada, utrzymanie procedur i doprowadzenie ludzi do poziomu, na którym nie tylko widzą alert, ale jeszcze wiedzą, co z nim zrobić. Koszt rośnie wraz z liczbą źródeł logów, endpointów, retencją danych i oczekiwanym SLA, więc przed podpisaniem umowy trzeba to policzyć bardzo trzeźwo.
Gdy wybór modelu jest już jasny, największe ryzyko przenosi się z poziomu strategii na poziom codziennej pracy. I właśnie tam pojawiają się błędy, które potrafią zabić nawet dobrze zaprojektowany program.Najczęstsze błędy, przez które SOC nie daje wartości
Największy problem z SOC-em nie polega na tym, że „nie działa”. Zwykle działa, tylko nie daje wartości proporcjonalnej do kosztu, bo coś po drodze zostało źle ustawione. Widziałem to wielokrotnie: mnóstwo dashboardów, kilka tysięcy alertów i mało realnych decyzji.
- Za mało danych wejściowych - jeśli logi nie obejmują chmury, tożsamości, endpointów i kluczowych aplikacji, analityk patrzy na niepełny obraz.
- Brak inwentaryzacji aktywów - bez wiedzy o tym, co jest krytyczne, nie da się sensownie ustawić priorytetów ani reguł eskalacji.
- Przeciążenie alertami - gdy wszystko jest pilne, nic nie jest pilne. To prosty przepis na wypalenie zespołu i utratę zaufania do narzędzia.
- Brak playbooków - bez opisanych scenariuszy reakcja zależy od pamięci ludzi, a to w bezpieczeństwie jest zbyt kruche.
- Brak prawa do działania - SOC, który nie może zablokować konta, odłączyć hosta albo zatrzymać procesu, jest centrum obserwacji, nie ochrony.
- Złe metryki - liczenie liczby alertów nie mówi prawie nic. Lepiej patrzeć na MTTD, czyli średni czas wykrycia, oraz MTTR, czyli średni czas reakcji i naprawy.
Do tego dochodzi błąd organizacyjny, który moim zdaniem jest najgroźniejszy: brak połączenia między SOC a resztą firmy. Jeśli zespół bezpieczeństwa nie ma kontaktu z IT, helpdeskiem, właścicielami systemów i zarządem, to nawet szybko wykryty incydent będzie rozwiązywany za wolno. A skoro wiemy już, co najczęściej się psuje, pozostaje pytanie najważniejsze z perspektywy decydenta: kiedy taki wysiłek ma realny sens.
Kiedy inwestycja w SOC ma sens i co sprawdzić przed wdrożeniem
W polskich firmach SOC zaczyna mieć sens wtedy, gdy pojedynczy incydent może realnie zatrzymać sprzedaż, produkcję, obsługę klientów albo dostęp do danych. Najczęściej widzę to w organizacjach działających 24/7, firmach z dużą liczbą pracowników zdalnych, podmiotach z wieloma integracjami zewnętrznymi oraz wszędzie tam, gdzie zgodność, audyt i odporność operacyjna przestały być dodatkiem, a stały się warunkiem działania.
- Sprawdź, jakie źródła logów są obowiązkowe, a jakie tylko „miłe do posiadania”.
- Ustal SLA na triage, eskalację i reakcję, zamiast zakładać, że „będzie szybko”.
- Zweryfikuj, kto ma prawo podjąć decyzję o izolacji stacji, blokadzie konta lub wyłączeniu usługi.
- Poproś o przykładowe playbooki i raporty, bo to one pokazują dojrzałość, a nie sam opis oferty.
- Upewnij się, że SOC umie pracować z waszymi systemami ticketowymi, IAM-em, EDR-em i chmurą.
- Sprawdź, jak długo przechowywane są logi i jak wygląda do nich dostęp w razie incydentu.
Jeśli miałbym zostawić jedną praktyczną wskazówkę, brzmiałaby tak: wybieraj SOC nie po liczbie ekranów, tylko po jakości decyzji, które pomaga podjąć w pierwszych minutach ataku. Gdy ten warunek jest spełniony, monitoring przestaje być kosztem administracyjnym, a staje się realną warstwą obrony całej organizacji.