
SQL to podstawowe narzędzie do pracy z danymi w relacyjnych bazach: pozwala pobierać rekordy, filtrować je, łączyć między tabelami i bezpiecznie je zmieniać. Dla osoby uczącej się programowania to jeden z najszybszych sposobów, żeby przejść od teorii do realnej pracy na danych, bo już kilka dobrze zrozumianych poleceń daje bardzo konkretne efekty. W tym artykule pokazuję, jak działa ten język, od czego zacząć i które błędy najczęściej psują wyniki.
Najważniejsze rzeczy, które warto wiedzieć od razu
- SQL służy do pracy z relacyjnymi bazami danych, czyli tabelami połączonymi kluczami i zależnościami.
- Najbardziej praktyczne polecenia na start to SELECT, WHERE, ORDER BY, GROUP BY i JOIN.
- To język deklaratywny: opisujesz wynik, a nie krok po kroku sposób dojścia do niego.
- Najwięcej problemów sprawiają źle napisane łączenia tabel, brak warunku filtrowania i mylenie WHERE z HAVING.
- Relacyjne bazy są bardzo mocne tam, gdzie liczy się spójność danych, raportowanie i transakcje.
- Różne silniki bazodanowe mają własne niuanse składni, ale rdzeń pracy pozostaje podobny.
Czym jest SQL i kiedy naprawdę się przydaje
W praktyce traktuję SQL jako język rozmowy z relacyjną bazą danych. Nie jest to ogólny język programowania w stylu Pythona czy Javy, tylko narzędzie zaprojektowane po to, by pobierać, zmieniać i porządkować dane zapisane w tabelach. To ważne rozróżnienie, bo od razu ustawia oczekiwania: tutaj nie buduje się całej aplikacji, tylko precyzyjnie zarządza informacją.
Najlepiej widać to na prostym modelu: baza przechowuje dane o klientach, zamówieniach, produktach i płatnościach w osobnych tabelach, a SQL pozwala je sensownie zestawiać. Dzięki temu jeden system może obsłużyć sprzedaż, raporty, historię działań i kontrolę dostępu. Właśnie dlatego ten język tak długo utrzymuje się w centrum systemów biznesowych.
Ja zwykle tłumaczę to tak: jeśli dane mają strukturę, powtarzalne zależności i potrzebę raportowania, relacyjna baza jest naturalnym wyborem. SQL sprawdza się przy panelach administracyjnych, systemach e-commerce, księgowości, analizie danych, CRM-ach i wszędzie tam, gdzie ważna jest spójność oraz możliwość zadawania złożonych pytań o dane. To prowadzi wprost do pytania, jak wygląda samo zapytanie i z czego się składa.
Jak zbudowane jest pierwsze zapytanie
Najprostsze zapytanie zwykle zaczyna się od SELECT, który wskazuje, jakie kolumny chcesz zobaczyć. Potem pojawia się FROM, czyli tabela źródłowa, a następnie opcjonalne elementy, takie jak WHERE do filtrowania czy ORDER BY do sortowania. Ta kolejność jest ważna nie dlatego, że trzeba ją zapamiętać jak formułkę, ale dlatego, że pokazuje logikę myślenia o danych.
SELECT imie, nazwisko, miasto
FROM klienci
WHERE miasto = 'Warszawa'
ORDER BY nazwisko ASC;W tym przykładzie wynik obejmuje tylko trzy kolumny, tylko wiersze z Warszawy i jest posortowany alfabetycznie po nazwisku. To już wystarczy, żeby zobaczyć, jak bardzo precyzyjna może być praca z danymi bez pisania długiego kodu. Właśnie dlatego SQL tak szybko daje poczucie kontroli.
| Element | Co robi | Po co go używam |
|---|---|---|
| SELECT | Wybiera kolumny, które mają trafić do wyniku | Gdy nie potrzebuję całej tabeli, tylko konkretnych pól |
| FROM | Wskazuje tabelę lub tabele źródłowe | Gdy wiem, skąd mają pochodzić dane |
| WHERE | Odfiltrowuje wiersze przed dalszym przetwarzaniem | Gdy interesuje mnie tylko część rekordów |
| ORDER BY | Ustala kolejność wyników | Gdy wynik ma być czytelny albo rankingowy |
Jeśli ktoś zaczyna naukę od razu od trudnych funkcji, łatwo się gubi. Ja wolę najpierw dobrze opanować ten prosty szkielet, bo z niego składa się większość codziennej pracy. Następny krok to łączenie danych z różnych tabel, a tam robi się naprawdę ciekawie.
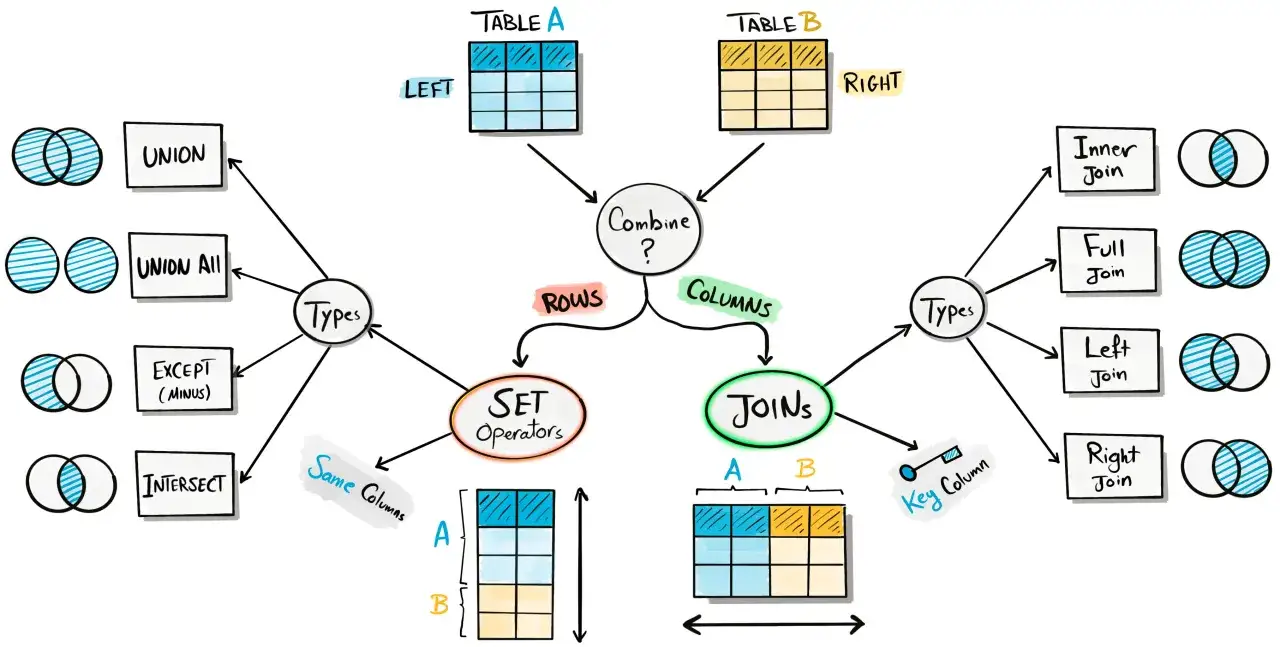
Jak łączyć tabele, żeby dane miały sens
Relacyjne bazy są zbudowane wokół powiązań. Jedna tabela trzyma klientów, druga zamówienia, trzecia pozycje zamówień. Żeby dostać pełny obraz, trzeba je połączyć przez klucze główne i obce. Właśnie do tego służy JOIN - łączy rekordy na podstawie logicznej relacji, a nie przypadkowego dopasowania.
SELECT k.imie, k.nazwisko, z.data_zamowienia
FROM klienci k
JOIN zamowienia z ON z.klient_id = k.id;Ten przykład pokazuje klasyczne połączenie klienta z jego zamówieniami. Najważniejszy fragment to warunek po ON, bo to on mówi bazie, które wiersze pasują do siebie. Jeśli warunek jest zły albo go brakuje, wynik potrafi eksplodować liczbą niepotrzebnych rekordów. To jeden z powodów, dla których JOIN budzi respekt u początkujących.
| Typ połączenia | Co zwraca | Kiedy ma sens |
|---|---|---|
| INNER JOIN | Tylko rekordy, które mają dopasowanie po obu stronach | Gdy interesują mnie wyłącznie kompletne pary danych |
| LEFT JOIN | Wszystkie rekordy z lewej tabeli i pasujące rekordy z prawej | Gdy nie chcę zgubić głównej listy, nawet jeśli brak dopasowania |
W praktyce największa różnica między dobrym a słabym zapytaniem nie polega na samym użyciu JOIN, tylko na jakości relacji między tabelami. Jeżeli model danych jest spójny, łączenia są naturalne. Jeśli model jest chaotyczny, zapytania zaczynają przypominać gaszenie pożaru. Gdy masz już połączenia pod kontrolą, kolejne wyzwanie to filtrowanie i liczenie wyników.
Sortowanie, filtrowanie i agregacje w praktyce
W realnej pracy rzadko potrzebuję całej tabeli bez ograniczeń. Zwykle interesuje mnie fragment danych: aktywni klienci z jednego miasta, suma sprzedaży w danym miesiącu, liczba zamówień na kategorię albo średnia wartość koszyka. Do tego służą filtry, sortowanie i funkcje agregujące. To właśnie ten obszar sprawia, że SQL staje się narzędziem analitycznym, a nie tylko techniczną składnią.
SELECT miasto, COUNT(*) AS liczba_klientow
FROM klienci
WHERE status = 'aktywny'
GROUP BY miasto
HAVING COUNT(*) >= 10
ORDER BY liczba_klientow DESC;Tu dzieje się kilka rzeczy naraz. WHERE wybiera tylko aktywnych klientów, GROUP BY grupuje ich według miasta, COUNT(*) liczy rekordy w każdej grupie, a HAVING odrzuca miasta zbyt małe, by były istotne w zestawieniu. To dobre miejsce, żeby zapamiętać jedną zasadę: WHERE działa przed grupowaniem, HAVING po grupowaniu.
Najczęściej używane funkcje agregujące to COUNT, SUM, AVG, MIN i MAX. Każda z nich odpowiada na inne pytanie, ale wszystkie mają wspólny mianownik: upraszczają surowe dane do informacji, którą da się odczytać. Jeśli pracujesz z raportami, to właśnie agregacje będą jednym z najczęściej używanych narzędzi. Warto przy tym uważać na kilka typowych pułapek, bo to one najczęściej psują wynik.
Najczęstsze błędy, które psują wyniki
Na tym etapie większość problemów nie wynika z samego języka, tylko z pośpiechu. Z mojego doświadczenia początkujący najczęściej wpadają w te same pułapki:
- Brak warunku WHERE przy UPDATE lub DELETE - jedno takie zapytanie potrafi zmienić albo usunąć całą tabelę.
- JOIN bez zrozumienia relacji - wynik bywa za duży, powielony albo logicznie błędny.
- SELECT * w dużych tabelach - wygodne na start, ale niepotrzebnie obciąża wynik i utrudnia kontrolę nad kolumnami.
- Mylenie WHERE z HAVING - filtr nie działa tam, gdzie powinien, bo jest użyty po złej stronie grupowania.
- Ignorowanie wartości NULL - porównania z pustymi danymi nie zachowują się tak, jak wielu osobom intuicyjnie się wydaje.
- Zakładanie, że każdy silnik ma identyczną składnię - rdzeń jest podobny, ale detale różnią się między bazami.
Najbardziej niebezpieczne są błędy, które nie generują od razu komunikatu o problemie, tylko zwracają pozornie poprawny, ale fałszywy wynik. Dlatego przy pracy z danymi zawsze patrzę nie tylko na to, czy zapytanie działa, ale też czy odpowiedź naprawdę ma sens. To prowadzi do ważnego porównania: kiedy warto używać relacyjnej bazy, a kiedy lepiej sprawdza się inne podejście.
SQL a inne podejścia do danych
Nie traktuję relacyjnych baz i rozwiązań dokumentowych jako wojny technologii. To po prostu różne odpowiedzi na różne potrzeby. Jeśli dane mają wyraźną strukturę, dużo zależności i wymagają spójnych transakcji, relacyjny model zwykle wygrywa. Jeśli schemat często się zmienia albo dokumenty mają bardzo różne kształty, elastyczniejsze magazyny danych mogą być wygodniejsze.
| Cecha | Relacyjne bazy i SQL | Podejście dokumentowe |
|---|---|---|
| Struktura danych | Dobrze działa przy tabelach, kolumnach i relacjach | Lepiej znosi zróżnicowane, mniej regularne dokumenty |
| Spójność | Silna kontrola integralności i transakcji | Większa elastyczność, czasem kosztem ścisłej spójności |
| Łączenie danych | Bardzo mocne dzięki JOIN | Zwykle mniej naturalne lub kosztowniejsze |
| Zmiana schematu | Wymaga większej dyscypliny | Łatwiej ją wprowadzać na bieżąco |
| Zastosowanie | Raporty, systemy biznesowe, finanse, CRM, e-commerce | Treści, zdarzenia, szybko zmieniające się modele danych |
Warto też pamiętać, że sam język ma różne dialekty. PostgreSQL, MySQL, SQL Server, SQLite i Oracle opierają się na tym samym rdzeniu, ale różnią się detalami: funkcjami dat, paginacją wyników, operacjami na tekstach czy składnią niektórych rozszerzeń. Dlatego ktoś, kto dobrze pisał zapytania w jednym środowisku, nie zawsze od razu czuje się swobodnie w innym. Gdy to już rozumiesz, nauka staje się znacznie prostsza i bardziej przewidywalna.
Jak uczyć się zapytań, żeby szybko wejść na poziom praktyczny
Ja zaczynam naukę od małych, przewidywalnych zbiorów danych. To najlepszy sposób, żeby zobaczyć, co dokładnie robi każde polecenie, zamiast zgadywać na dużych tabelach. W praktyce sprawdza się taki rytm pracy:
- Najpierw piszę proste SELECT z jedną lub dwiema kolumnami.
- Później dokładam WHERE, żeby sprawdzić, jak filtr wpływa na wynik.
- Następnie ćwiczę ORDER BY i obserwuję zmianę kolejności danych.
- Potem przechodzę do JOIN i łączę dwie tabele na prostym przykładzie.
- Dopiero na końcu dokładam grupowanie, agregacje i bardziej złożone warunki.
Pomaga też bardzo prosta zasada: jedna nowa rzecz na jedno nowe zapytanie. Dzięki temu od razu wiadomo, co działa, co nie działa i z czego wynika różnica. Jeśli coś zwraca zły wynik, poprawiam najpierw logikę, a dopiero później myślę o wydajności. To oszczędza czas i uczy porządku w myśleniu.
W dobrze napisanych zapytaniach widać dyscyplinę: konkretne kolumny, czytelne aliasy, jasne warunki i brak zbędnych skrótów. Taki styl robi dużą różnicę zarówno podczas nauki, jak i w pracy zespołowej. Jeśli opanujesz te podstawy, przejście do bardziej zaawansowanych tematów, takich jak indeksy, widoki czy transakcje, będzie już naturalnym kolejnym krokiem.