
Dobre bazy danych decydują o tym, czy aplikacja będzie przewidywalna, szybka i łatwa w rozwijaniu, czy po kilku sprintach zacznie tonąć w obejściach. W tym tekście pokazuję, jak działa warstwa danych w kodzie, czym różni się model relacyjny od nierelacyjnego i jak wybrać rozwiązanie do realnego projektu. Dorzucam też praktyczne wskazówki o indeksach, transakcjach, schemacie i błędach, które najczęściej wychodzą dopiero na produkcji.
Najpierw model danych, potem technologia, dopiero na końcu optymalizacje
- Najważniejsze są wzorce zapytań, a nie moda na konkretny silnik.
- Model relacyjny lepiej sprawdza się tam, gdzie liczy się spójność i transakcje.
- Rozwiązania dokumentowe dają więcej swobody, ale wymagają większej dyscypliny w kodzie.
- Indeksy przyspieszają odczyt, lecz każda dodatkowa struktura kosztuje zapis i miejsce.
- Normalizacja ogranicza chaos, a transakcje i ograniczenia bronią jakości danych.
- Najczęstszy błąd to wybór narzędzia pod trend, nie pod realne potrzeby projektu.
Jak działa warstwa danych w aplikacji
W praktyce nie pracujesz bezpośrednio z „magazynem rekordów”, tylko z całym silnikiem, który dba o zapis, odczyt, blokady, walidację i zapytania. To właśnie system zarządzania danymi decyduje o tym, czy operacje będą spójne, jak szybko wrócą wyniki i co stanie się, gdy kilka procesów spróbuje zmienić ten sam fragment informacji naraz.
W kodzie najczęściej spotkasz cztery podstawowe operacje: tworzenie, odczyt, aktualizację i usuwanie danych, czyli CRUD. Dla programisty ważniejsze od samej nazwy jest to, że każda z tych operacji ma inną cenę. Odczyt możesz przyspieszać indeksami, zapis trzeba chronić transakcjami, a struktura danych powinna odpowiadać temu, jak aplikacja faktycznie pyta o informacje. Łatwo też przecenić ORM, czyli warstwę mapującą obiekty na rekordy. Ułatwia start, ale nie zastąpi zrozumienia zapytań ani planu wykonania.Jeśli myślisz o danych jak o jednym z fundamentów architektury, a nie dodatku do logiki biznesowej, reszta decyzji staje się dużo prostsza. Z tego przechodzę do najważniejszego podziału, który naprawdę wpływa na kształt projektu.
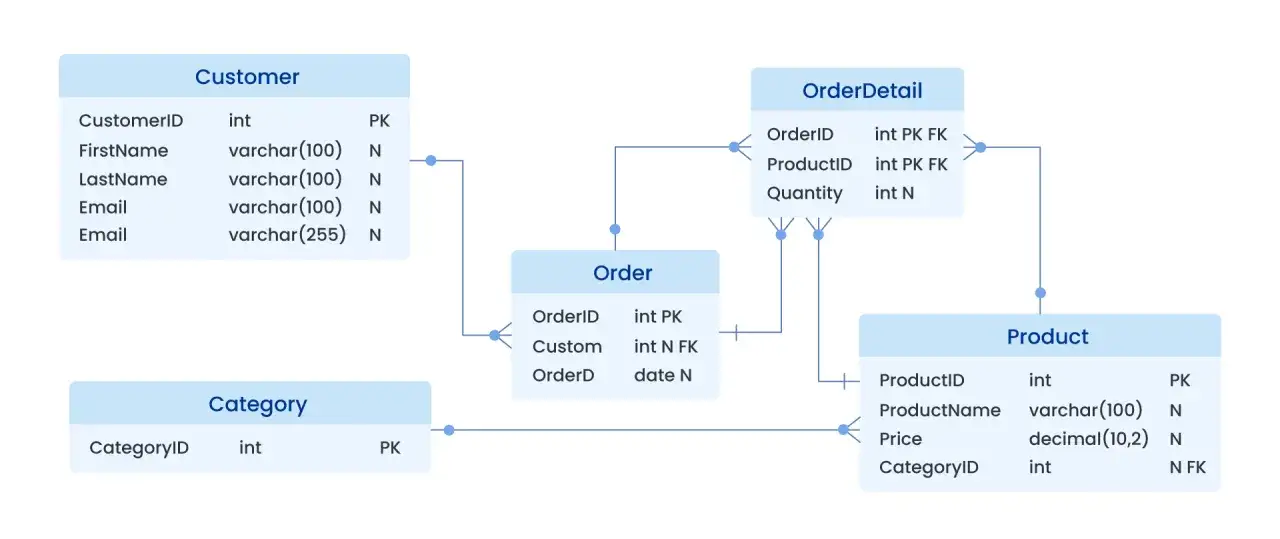
Relacyjne i nierelacyjne modele bez marketingowych skrótów
Ja patrzę na ten podział bardzo praktycznie: model relacyjny daje porządek i ścisłość, a nierelacyjny więcej elastyczności. To nie jest wojna technologii, tylko wybór między innym sposobem myślenia o danych, relacjach i zmianach w produkcie.
| Cecha | Model relacyjny | Model nierelacyjny |
|---|---|---|
| Struktura | Tabele, wiersze, kolumny i jasno opisane relacje | Dokumenty, pary klucz-wartość, grafy lub inne struktury zależnie od potrzeb |
| Spójność | Silna kontrola, transakcje i ograniczenia na poziomie schematu | Większa swoboda, ale też większa odpowiedzialność po stronie aplikacji |
| Zmiana schematu | Wymaga migracji i planowania | Łatwiej rozpocząć pracę z niestabilną strukturą danych |
| Zapytania | Świetne do łączenia danych, raportów i złożonych filtrów | Dobre, gdy odczyt dotyczy jednego dokumentu lub prostego wzorca dostępu |
| Typowe zastosowanie | Systemy transakcyjne, e-commerce, finanse, panele administracyjne | Treści o zmiennej strukturze, logi, profile, niektóre systemy eventowe |
| Ryzyko | Sztywniejszy start, jeśli model zmienia się co tydzień | Rozjechanie struktury, jeśli nie ma walidacji i dyscypliny w kodzie |
W praktyce największy błąd polega na tym, że ktoś wybiera model po opisie marketingowym, a nie po tym, jakie zapytania wykona aplikacja tysiące razy dziennie. Gdy ten wybór jest już sensowny, zaczyna się prawdziwa inżynieria: strojenie odczytu, ochrona spójności i pilnowanie kosztów zapisu.
Co naprawdę przyspiesza odczyt i stabilizuje zapis
Nie ma jednego triku, który nagle zrobi z wolnej aplikacji szybką. Najwięcej daje kilka prostych decyzji podejmowanych konsekwentnie: rozsądne indeksy, sensowna normalizacja, transakcje dla zmian krytycznych oraz kopie zapasowe, które naprawdę da się odtworzyć. To są rzeczy mało efektowne, ale właśnie one ratują projekt, gdy liczba użytkowników rośnie albo pojawiają się błędy w produkcji.Indeksy nie są darmowe
Indeks działa trochę jak spis treści. Przyspiesza wyszukiwanie po polach, po których często filtrujesz, sortujesz albo łączysz dane. Nie oznacza to jednak, że każda kolumna powinna go mieć. Każdy dodatkowy indeks zajmuje miejsce i spowalnia zapis, bo silnik musi aktualizować nie tylko rekord, ale też strukturę pomocniczą. Jeśli indeksów robi się za dużo, aplikacja zaczyna płacić za każdą operację, nawet jeśli odczyt wygląda dobrze na papierze.
Najbardziej opłaca się indeksować to, co naprawdę występuje w filtrach, JOIN-ach i sortowaniach. Indeks na kolumnie o bardzo małej różnorodności, na przykład z samymi wartościami tak i nie, często niewiele daje. Tu liczy się selektywność, czyli to, jak bardzo filtr zawęża zbiór wyników.
Normalizacja porządkuje, ale nie za wszelką cenę
Normalizacja to uporządkowanie danych tak, by nie powielać tych samych informacji bez potrzeby i nie tworzyć zależności, które później trudno utrzymać. W większości aplikacji wystarczają podstawowe postacie normalne, zwykle do trzeciej. To dobry punkt równowagi: mniej duplikacji, mniej anomalii przy aktualizacji i prostsze utrzymanie.
Jednocześnie nie warto robić z normalizacji religii. Czasem lekkie denormalizowanie przyspiesza odczyt albo upraszcza raportowanie. Ja robię to tylko wtedy, gdy widzę realny problem wydajnościowy lub bardzo kosztowne łączenia. Inaczej łatwo wymienić jeden kłopot na drugi.
Transakcje chronią przed połówkowym zapisem
Transakcja to logiczna całość: albo wszystkie zmiany się udają, albo żadna nie zostaje zapisana. To ważne przy płatnościach, rezerwacjach, stanach magazynowych i każdym miejscu, gdzie błędny częściowy zapis byłby dla aplikacji groźny. Z tym wiążą się właściwości ACID:
- atomowość oznacza, że operacja wykonuje się w całości albo wcale,
- spójność pilnuje, by dane kończyły w dozwolonym stanie,
- izolacja ogranicza mieszanie się równoległych zmian,
- trwałość zapewnia, że zatwierdzone dane przetrwają awarię.
W systemach rozproszonych czasem akceptuje się chwilowe opóźnienie spójności między replikami, ale to świadomy kompromis, a nie przypadkowa niedoróbka. Jeśli projekt tego wymaga, trzeba to zaplanować od początku, nie „naprawiać” po fakcie.
Przeczytaj również: Jak powiększyć tabelę w HTML i uniknąć problemów z wyświetlaniem
Kopie i repliki nie pełnią tej samej roli
Replikacja zwiększa dostępność i pomaga przy odczycie, natomiast kopia zapasowa chroni przed utratą danych. Jedno nie zastępuje drugiego. Jeśli nie przetestujesz odtworzenia backupu, to tak naprawdę nie wiesz, czy backup działa. To jeden z tych obszarów, w których pewność bierze się wyłącznie z ćwiczeń, nie z założeń.
Gdy te elementy są pod kontrolą, można dobrać technologię pod konkretny projekt, zamiast dopasowywać projekt do narzędzia.
Jak dobrać technologię do rodzaju projektu
Najlepsza heurystyka, jaką stosuję, jest zaskakująco prosta: najpierw sprawdzam, jakie zapytania będą wykonywane najczęściej, jak często zmieni się schemat i czy projekt wymaga mocnej spójności. Dopiero potem patrzę na konkretny silnik. Poniższa tabela porządkuje ten wybór bez udawania, że istnieje jedno uniwersalne rozwiązanie.
| Rodzaj projektu | Częsty wybór | Dlaczego to działa | Na co uważać |
|---|---|---|---|
| Sklep internetowy, płatności, ERP | PostgreSQL lub MySQL | Transakcje, spójność, wygodne relacje i raporty | Nie projektuj schematu bez myślenia o indeksach i migracjach |
| Panel administracyjny, CMS, system treści | PostgreSQL | Dobry kompromis między elastycznością a kontrolą danych | Zbyt dużo pól tekstowych bez walidacji szybko robi bałagan |
| Aplikacja mobilna, narzędzie lokalne, offline-first | SQLite | Lekki silnik, prosty start, brak ciężkiej administracji serwera | Przy większej współbieżności potrzebujesz innego podejścia |
| Profile użytkowników, katalogi, logi, dane o zmiennej strukturze | MongoDB lub inny model dokumentowy | Łatwiej przechowywać rekordy, które nie mają identycznego kształtu | Bez walidacji dokumenty szybko zaczynają żyć własnym życiem |
| Sesje, cache, liczniki, proste odczyty klucz-wartość | Redis | Bardzo szybki dostęp i mało złożony model użycia | Nie próbuj zastępować nim głównej bazy dla złożonych relacji |
To prowadzi do następnego problemu, który widzę bardzo często: nawet dobry wybór technologii można zepsuć złym sposobem pracy. I właśnie o tym warto mówić wprost, bo to najdroższe błędy.
Najczęstsze błędy, które wychodzą dopiero po wdrożeniu
- Modelowanie pod jeden ekran, nie pod cały produkt. Schema działa na MVP, ale po kilku funkcjach zaczyna pękać. Lepiej zaprojektować dane pod kilka kluczowych przepływów niż pod pojedynczy formularz.
- Brak migracji od początku. Ręczne zmiany w schemacie szybciej prowadzą do chaosu niż do szybkości. Migracje są nudne, ale właśnie dlatego są dobre.
- Indeksowanie wszystkiego „na wszelki wypadek”. To często poprawia jeden przypadek użycia, a pogarsza zapis i utrzymanie całego systemu.
- Trzymanie dowolnej struktury bez walidacji. Elastyczność bez reguł kończy się tym, że dwa rekordy wyglądające podobnie mają inne pola, typy albo znaczenie.
- Brak testu odtworzenia kopii zapasowej. Backup, którego nie da się przywrócić, daje tylko poczucie bezpieczeństwa.
- Ufanie ORM-owi bardziej niż własnym zapytaniom. Warstwa abstrakcji pomaga, ale potrafi też ukryć kosztowne zapytania, nadmiarowe doładowania danych i niepotrzebne JOIN-y.
Jeśli miałbym wskazać jeden wspólny mianownik tych błędów, byłby to brak myślenia o danych jak o kontrakcie między kodem a produktem. Gdy ten kontrakt jest jasny, ostatni krok to ustawienie zdrowych podstaw od pierwszego dnia pracy nad projektem.
Co warto ustawić od pierwszego commita, żeby warstwa danych nie rozpadła się później
Przy nowym projekcie zaczynam od bardzo przyziemnej listy, bo to ona później oszczędza najwięcej czasu. Najpierw spisuję encje i relacje, potem zapisuję 5-10 najważniejszych zapytań, które aplikacja wykona naprawdę często. Dopiero na tej podstawie wybieram silnik, indeksy i sposób migracji.
- Opisz dane tak, jak będą używane, a nie tak, jak najłatwiej je zapisać.
- Dodaj migracje i walidację schematu od pierwszego dnia.
- Ustal, które operacje muszą być transakcyjne, a które mogą być prostsze.
- Wybierz kilka sensownych indeksów zamiast tworzyć ich dziesiątki.
- Włącz monitoring wolnych zapytań i test przywracania kopii.
- Dokumentuj decyzje architektoniczne, zanim staną się pamięcią jednej osoby w zespole.
Tak właśnie podchodzę do tematu w praktyce: najpierw porządek w modelu, potem technologia, a dopiero później strojenie wydajności. Dzięki temu warstwa danych nie staje się hamulcem rozwoju, tylko stabilnym fundamentem aplikacji.