
Atak rozproszony typu DDoS potrafi zatrzymać sklep internetowy, API, panel klienta albo cały serwis, nawet jeśli sama aplikacja nie ma klasycznej luki bezpieczeństwa. Problem polega na tym, że ruch napływa z wielu źródeł naraz i udaje normalne korzystanie z usługi, więc przeciążenie bywa trudne do odróżnienia od prawdziwego zainteresowania. W tym artykule pokazuję, jak taki atak działa, po czym go rozpoznać i które zabezpieczenia faktycznie podnoszą odporność infrastruktury.
Najkrócej: atak DDoS ma odciąć usługę, a skuteczna obrona zaczyna się zanim ruch spuchnie
- Napastnik zalewa usługę ruchem z wielu źródeł, żeby wyczerpać łącze, serwer albo zasoby aplikacji.
- Najczęściej spotkasz trzy klasy ataków: wolumetryczne, protokołowe i aplikacyjne.
- W obronie najlepiej działa warstwowe podejście: CDN, WAF, rate limiting, Anycast i plan reakcji.
- Sam firewall nie wystarczy, jeśli atak trafia w łącze albo w warstwę aplikacji.
- Największy błąd to reagowanie dopiero wtedy, gdy serwis już jest niedostępny.
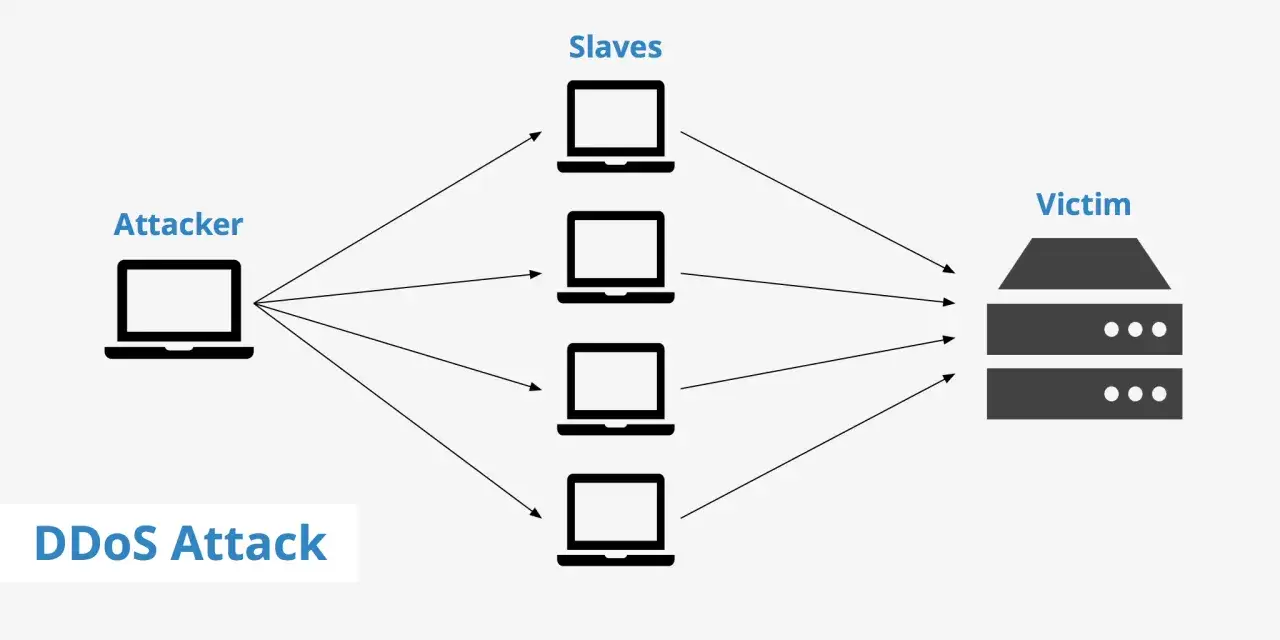
Jak działa atak rozproszony i dlaczego jest groźniejszy od zwykłego przeciążenia
Najprościej mówiąc, napastnik nie musi „włamywać się” do systemu, żeby wyrządzić szkody. Wystarczy, że zasypie go ruchem z wielu komputerów, serwerów, urządzeń IoT albo przejętych maszyn w botnecie, czyli sieci urządzeń sterowanych zdalnie przez atakującego. Efekt jest banalny w założeniu, ale bardzo skuteczny w praktyce: łącze się zatyka, kolejki rosną, aplikacja przestaje odpowiadać, a użytkownik widzi timeouty, błędy 502 albo kompletny brak dostępu.
Różnica między zwykłym skokiem ruchu a atakiem jest istotna. Przy normalnym piku zainteresowania ruch ma zwykle sensowny profil: przychodzi z przewidywalnych kanałów, dotyczy konkretnych podstron i da się go obsłużyć przez skalowanie. Przy ataku wzorzec jest nienaturalny, często chaotyczny, a źródła ruchu są rozproszone i zmienne. Z mojego doświadczenia to właśnie ta pozorna „normalność” ruchu najczęściej spóźnia reakcję zespołu.
Trzeba też pamiętać, że celem nie zawsze jest całkowite wyłączenie serwisu. Czasem chodzi o wymuszenie kosztów, odwrócenie uwagi od innego incydentu albo zszarpanie pracy zespołu wsparcia. CISA zwraca uwagę, że taki atak bywa zasłoną dymną dla innych działań, więc traktowanie go jako pojedynczego problemu z dostępnością bywa zbyt wąskie. To prowadzi nas do tego, jak rozpoznać rodzaj ataku i dobrać właściwą obronę.
Najczęstsze typy ataków i gdzie uderzają
W praktyce nie ma jednego „uniwersalnego” wzorca. CISA wyróżnia trzy główne klasy: wolumetryczne, protokołowe i aplikacyjne. Każda obciąża inny fragment infrastruktury, więc inne narzędzia będą miały sens w każdym z tych przypadków.
| Typ ataku | Co jest celem | Jak wygląda w praktyce | Co zwykle pomaga |
|---|---|---|---|
| Wolumetryczny | Łącze i przepustowość | Ogromna liczba pakietów lub zapytań, które „zalewają” dostęp do usługi | CDN, ochrona upstream, scrubbing, Anycast |
| Protokołowy | Stos sieciowy i zasoby urządzeń pośrednich | Wykorzystanie mechanizmów TCP/UDP, SYN flood, amplification, reflection | Filtry na brzegu sieci, tuning urządzeń, reguły antyspoofingowe |
| Aplikacyjny | Backend, endpointy, bazę danych, logikę aplikacji | Ruch wygląda jak zwykłe żądania HTTP, ale wywołuje ciężkie operacje | WAF, rate limiting, cache, challenge, optymalizacja endpointów |
Wolumetryczne ataki są najłatwiejsze do zauważenia, ale nie zawsze najtrudniejsze do zatrzymania. Jeśli masz dobrego dostawcę CDN albo ochronę u operatora, część problemu znika zanim dotrze do twojej infrastruktury. Trudniejsze są ataki aplikacyjne, bo potrafią wyglądać jak ruch od realnych użytkowników. Właśnie dlatego sam firewall na końcu sieci nie rozwiązuje tematu.
Warto też znać pojęcie amplification, czyli wzmocnienia ruchu. Atakujący wysyła niewielkie zapytania do publicznych usług, a odpowiedzi są wielokrotnie większe i trafiają do ofiary. To tani sposób na generowanie dużego obciążenia, szczególnie gdy źródła są rozproszone. Kiedy rozumiesz ten mechanizm, łatwiej odróżnić typ zagrożenia od objawów zwykłego przeciążenia. Następny krok to rozpoznanie, czy właśnie dzieje się coś niepokojącego.
Jak rozpoznać incydent zanim serwis zwolni do zera
Najlepsza obrona zaczyna się od obserwacji. Jeżeli monitorujesz tylko uptime, dowiesz się o problemie za późno. Ja patrzę przede wszystkim na zmiany w zachowaniu ruchu: nagły wzrost żądań z nietypowych lokalizacji, powtarzalne wzorce z wielu adresów IP, skok liczby błędów 4xx i 5xx, wzrost latency oraz przeciążenie konkretnych endpointów.W praktyce alarmują mnie przede wszystkim takie sygnały:
- ruch rośnie gwałtownie, ale współczynnik konwersji albo aktywności użytkowników nie rośnie razem z nim;
- serwis działa wolno głównie na jednym etapie, na przykład przy logowaniu, wyszukiwaniu lub finalizacji zamówienia;
- logi pokazują wiele podobnych zapytań w krótkim czasie;
- rośnie zużycie CPU, pamięci, połączeń lub kolejki w load balancerze;
- DNS, API albo brama płatnicza zaczynają reagować niestabilnie;
- zespół wsparcia dostaje powtarzalne zgłoszenia o braku dostępności, ale wewnętrzne testy nie pokazują błędu aplikacji jako takiej.
Tu ważne jest jedno rozróżnienie: nie każdy skok ruchu to atak. Premiera produktu, kampania reklamowa albo publikacja w mediach też mogą wywołać przeciążenie. Różnica tkwi w jakości ruchu, a nie tylko w jego ilości. Jeśli ruch jest logicznie powiązany z kampanią, da się go przewidzieć i obsłużyć. Jeśli nie ma żadnego uzasadnienia biznesowego, a infrastruktura zaczyna się dławić, trzeba myśleć o incydencie bezpieczeństwa. Z takiej diagnozy naturalnie wynika pytanie: co faktycznie działa w obronie?
Jakie zabezpieczenia naprawdę mają sens
Najskuteczniejsza obrona jest warstwowa. Nie szukałbym jednego magicznego narzędzia, bo ono zwykle nie istnieje. Lepiej zbudować zestaw mechanizmów, które razem zatrzymują atak na różnych poziomach: od routingu, przez warstwę sieciową, aż po aplikację. Cloudflare opisuje tę filozofię bardzo pragmatycznie: automatyczna detekcja, Anycast, reguły ochronne i filtrowanie ruchu u źródła działają lepiej niż pojedyncza zapora postawiona na końcu łańcucha.
| Zabezpieczenie | Co robi | Kiedy ma największy sens | Ograniczenie |
|---|---|---|---|
| CDN | Rozprasza ruch i serwuje część treści z cache | Gdy serwis ma dużo zasobów statycznych lub publicznych stron | Nie chroni wszystkiego, jeśli atak idzie w dynamiczne API |
| WAF | Filtruje żądania HTTP i blokuje podejrzane wzorce | Przy atakach aplikacyjnych | Nie zatrzyma zalania łącza przed dotarciem do aplikacji |
| Rate limiting | Ogranicza liczbę żądań z jednego źródła lub do jednego endpointu | Gdy atak powtarza te same akcje | Źle ustawiony potrafi uciąć też prawdziwy ruch |
| Anycast | Rozsyła ruch do wielu lokalizacji pod tym samym adresem IP | Przy dużym, rozproszonym wolumenie | Wymaga odpowiedniej architektury po stronie dostawcy |
| Scrubbing center | Oczyszcza ruch i odrzuca złośliwe pakiety zanim trafią do celu | Przy mocnych atakach sieciowych | Liczy się przepustowość i jakość filtracji |
Do tego dochodzą proste rzeczy, które zaskakująco często robią różnicę: ukrycie originu za CDN-em, ograniczenie publicznego dostępu do paneli administracyjnych, zamknięcie zbędnych portów, sensowny cache, osobny plan dla DNS i testy obciążeniowe. Największy błąd, jaki widzę, to przekonanie, że „mamy firewall, więc jesteśmy bezpieczni”. Firewall jest tylko jednym z elementów. Gdy atak trafia w warstwę aplikacji albo w samo łącze, potrzebujesz czegoś więcej. To prowadzi do kolejnego pytania: jak zachować się w trakcie samego incydentu.
Co robić, gdy atak już trwa
W trakcie ataku liczy się tempo i dyscyplina. Nie próbuję wtedy „naprawiać wszystkiego naraz”, bo to zwykle kończy się chaosem. Najpierw zabezpieczam podstawową dostępność, potem dopiero analizuję szczegóły. Zespoły, które mają gotowy runbook, wygrywają czas, a w takich sytuacjach czas jest walutą.
- Potwierdź, czy to rzeczywiście atak, a nie legalny pik ruchu lub awaria zależnej usługi.
- Włącz gotowe reguły ochronne, challenge albo tryb wzmożonej filtracji na brzegu sieci.
- Ogranicz najbardziej kosztowne endpointy, jeśli są otwarte publicznie i nie są krytyczne dla działania.
- Skontaktuj się z dostawcą hostingu, CDN lub operatorem łącza, bo część filtracji musi zadziałać upstream.
- Zadbaj o komunikację z klientami i zespołem wsparcia, żeby nikt nie podejmował sprzecznych decyzji.
- Monitoruj także inne systemy, bo atak bywa odwróceniem uwagi od dodatkowych prób nadużyć.
Ta ostatnia rzecz jest szczególnie ważna. Jeśli ktoś zalewa cię ruchem, nie zakładaj automatycznie, że jedyny problem to wydajność. Sprawdzaj logowania, zmiany uprawnień, nietypowe zapytania do API i działania administracyjne. Dobre procedury reagowania obejmują nie tylko „jak odzyskać stronę”, ale też „jak nie przeoczyć drugiego wektora ataku”. Gdy sam incydent opadnie, najważniejsza praca dopiero się zaczyna.
Jak zbudować odporność, która działa także pod presją
Najlepsza ochrona przed tego typu incydentami nie polega na gaszeniu pożaru, tylko na zmniejszaniu szansy, że pożar w ogóle wybuchnie. W praktyce oznacza to regularne testy, sensowną architekturę i kilka bardzo przyziemnych decyzji organizacyjnych. Ja patrzę na to jak na proces, nie jak na pojedynczy zakup usługi.Najlepsza ochrona przed tego typu incydentami nie polega na gaszeniu pożaru, tylko na zmniejszaniu szansy, że pożar w ogóle wybuchnie. W praktyce oznacza to regularne testy, sensowną architekturę i kilka bardzo przyziemnych decyzji organizacyjnych. Ja patrzę na to jak na proces, nie jak na pojedynczy zakup usługi.Po pierwsze, trzymaj aktualny plan reakcji. Musi być krótki, zrozumiały i przypisany do ról: kto kontaktuje dostawcę, kto decyduje o zmianie reguł, kto komunikuje się z klientami. Po drugie, testuj granice. Jeśli nie wiesz, jak serwis zachowuje się przy nagłym wzroście ruchu, to nie masz odporności, tylko nadzieję. Po trzecie, projektuj system tak, żeby krytyczne funkcje miały minimalną liczbę zależności. Im mniej rzeczy musi działać jednocześnie, tym łatwiej utrzymać dostępność pod presją.
Warto też regularnie sprawdzać kilka częstych błędów:
- udostępniony publicznie origin bez dodatkowej ochrony;
- zbyt szerokie reguły rate limiting, które blokują realnych użytkowników;
- brak cache dla treści, które można bezpiecznie buforować;
- zależność od jednego punktu wejścia bez planu awaryjnego;
- brak ćwiczeń zespołu, przez co wszyscy pierwszy raz uczą się procedury w trakcie kryzysu.
Jeśli miałbym wskazać jedną rzecz, która daje największy zwrot, powiedziałbym: przygotowanie architektury i procedur zanim coś się wydarzy. To mniej efektowne niż zakup „ochrony premium”, ale w praktyce zdecydowanie skuteczniejsze. Dobrze zaprojektowana obrona nie eliminuje ryzyka całkowicie, ale mocno skraca czas przestoju i ogranicza panikę.
Ataki rozproszone pozostają skuteczne, bo wykorzystują prostą słabość internetu: każda usługa ma skończone zasoby, a napastnikowi wystarczy je wyczerpać szybciej, niż potrafisz je uzupełnić. Dlatego myślę o ochronie nie jako o jednym narzędziu, lecz o zestawie warstw, procedur i nawyków. Jeśli zbudujesz dobrą obserwowalność, ograniczysz powierzchnię ataku i przygotujesz plan reakcji, zyskasz realną przewagę jeszcze przed pierwszym alarmem.