
Sama sieć neuronowa nie jest magicznym czarnym pudełkiem, tylko modelem matematycznym, który zamienia dane wejściowe na przewidywanie przez serię prostych obliczeń. W tym artykule pokazuję, jak działa od środka, z czego się składa, gdzie ma sens w produktach internetowych i kiedy lepiej nie udawać, że jest najlepszym wyborem. Jeśli chcesz rozumieć AI bez marketingowej mgły, to jest dobry punkt startu.
Najważniejsze rzeczy o modelach neuronowych w kilku punktach
- To model inspirowany mózgiem, ale liczony zwykłą matematyką: wagami, sumami i funkcją aktywacji.
- Największe znaczenie mają warstwy, połączenia między nimi, funkcja straty i sposób uczenia.
- Model poprawia wynik stopniowo, porównując własną odpowiedź z oczekiwanym rezultatem.
- W internecie wspiera wyszukiwarki, rekomendacje, antyspam, moderację treści i analizę ruchu.
- Najczęstsze problemy to słabe dane, przeuczenie, koszty obliczeń i ograniczona interpretowalność.
Na czym polega model neuronowy
Najprościej mówiąc, to układ połączonych ze sobą jednostek obliczeniowych, które przetwarzają liczby i uczą się zależności w danych. Inspiracja biologicznym mózgiem jest tu ważna tylko jako punkt wyjścia: w praktyce chodzi o mnożenia, sumy ważone i nieliniowość, a nie o cyfrowy odpowiednik neuronu.
Ja lubię tłumaczyć ten model jako maszynę do wyłapywania wzorców tam, gdzie zwykłe reguły typu „jeśli to, to tamto” przestają wystarczać. Dzięki temu dobrze radzi sobie z danymi rozproszonymi, hałaśliwymi albo zbyt złożonymi, by opisać je ręcznie kilkoma prostymi zasadami. Gdy rozumiemy ten sens, łatwiej zobaczyć, skąd bierze się wynik, więc przechodzę do samego przepływu danych.
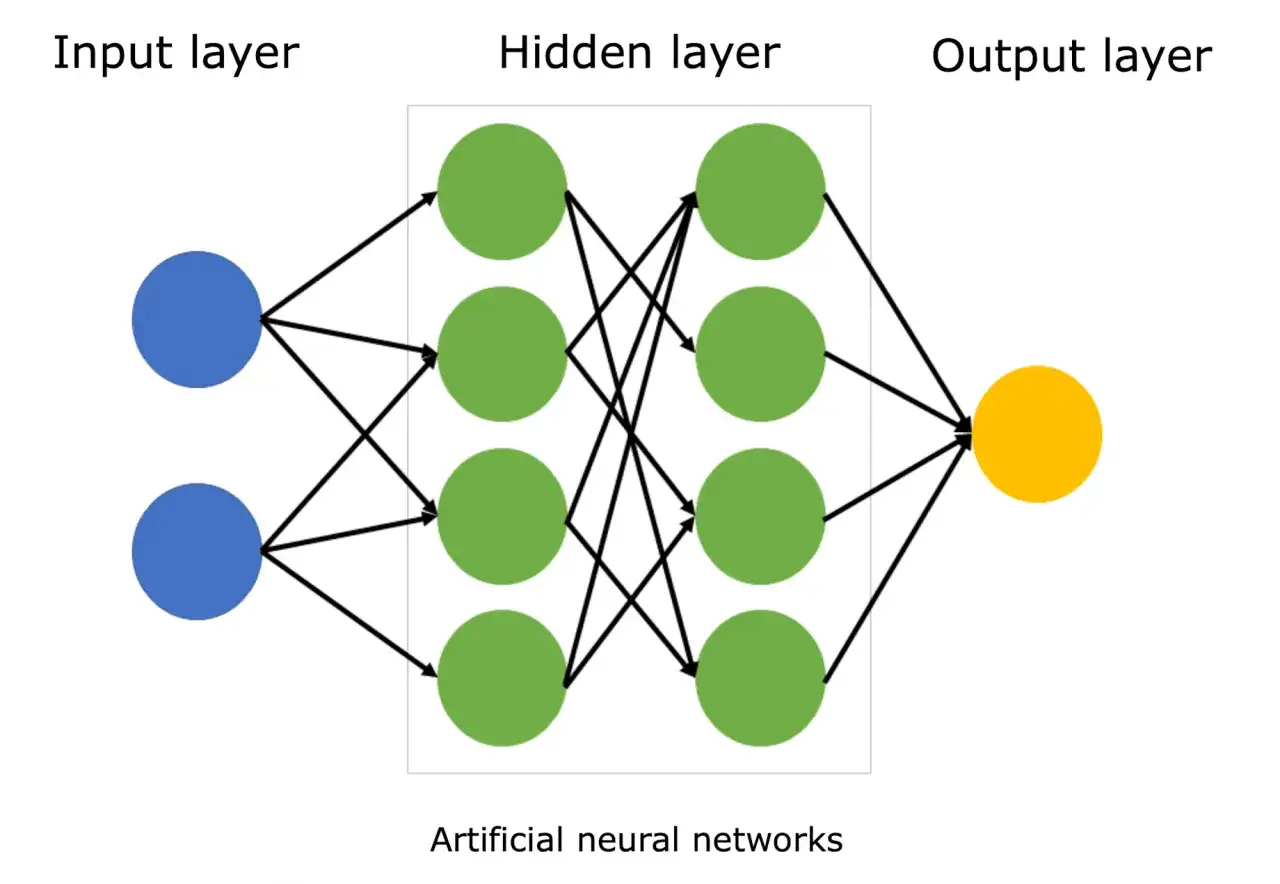
Jak działa taki model krok po kroku
W środku wszystko zaczyna się od danych wejściowych. Mogą to być liczby z formularza, cechy produktu, fragment tekstu, a nawet piksele obrazu. Każda wartość trafia do pierwszej warstwy, gdzie dostaje odpowiednią wagę, czyli liczbową miarę tego, jak mocno ma wpływać na wynik.
- Dane trafiają do warstwy wejściowej.
- Każde połączenie ma swoją wagę, a neuron liczy sumę ważoną.
- Do wyniku dochodzi bias, czyli stały składnik korygujący.
- Wartość przechodzi przez funkcję aktywacji, która wprowadza nieliniowość.
- Wynik trafia do kolejnej warstwy, aż finalnie model zwraca klasę, liczbę albo prawdopodobieństwo.
Najważniejszy detal jest taki, że bez funkcji aktywacji cały układ byłby dużo mniej elastyczny. W praktyce model zachowywałby się zbyt podobnie do prostszej regresji liniowej i nie łapałby złożonych zależności. To właśnie nieliniowość daje mu przewagę przy trudniejszych problemach, ale sama architektura to jeszcze nie wszystko. Trzeba ją dobrze skonfigurować, a potem nauczyć na danych.
Z czego składa się architektura i co naprawdę ma znaczenie
W praktyce najwięcej znaczą nie modne nazwy, tylko kilka twardych elementów. Jeśli jeden z nich jest źle dobrany, nawet solidny algorytm będzie dawał średni wynik. Dlatego patrzę na model nie jak na efektowną etykietę, ale jak na zestaw konkretnych decyzji projektowych.
| Element | Rola | Na co zwrócić uwagę |
|---|---|---|
| Warstwa wejściowa | Przyjmuje dane, np. tekst, liczby lub piksele | Im lepiej dane są uporządkowane, tym stabilniejszy wynik |
| Warstwy ukryte | Wyłapują wzorce pośrednie | Zbyt mało warstw ogranicza model, zbyt wiele podnosi koszt i ryzyko przeuczenia |
| Wagi | Określają siłę połączeń | To one zmieniają się najbardziej podczas treningu |
| Bias | Przesuwa wynik neuronu | Pomaga modelowi nie być zbyt sztywnym |
| Funkcja aktywacji | Wprowadza nieliniowość | Bez niej sieć traci zdolność łapania złożonych zależności |
| Funkcja straty | Mierzy błąd modelu | Im sensowniej dobrana, tym lepiej model uczy się właściwego celu |
Jeśli mam wskazać jeden element, który początkujący najczęściej niedoceniają, to właśnie funkcję aktywacji. Bez niej model potrafi „liczyć”, ale nie potrafi dobrze uczyć się złożonych zależności. Z tej architektury naturalnie wynika pytanie: kto i jak poprawia te parametry, skoro sam model na początku nic nie wie?
Jak przebiega uczenie i poprawianie błędów
Trening polega na wielokrotnym przepuszczaniu danych przez model, porównywaniu wyniku z oczekiwaniem i korygowaniu wag. Ja zwykle opisuję to jako pętlę prób i poprawek, tylko że zamiast intuicji działa tutaj matematyka.
- Model robi predykcję.
- Funkcja straty liczy błąd.
- Wsteczna propagacja pokazuje, które połączenia trzeba skorygować.
- Spadek gradientowy zmienia wagi małym krokiem.
- Proces powtarza się przez kolejne epoki, aż błąd spadnie do akceptowalnego poziomu.
Na małych zbiorach danych wystarczy czasem kilkaset lub kilka tysięcy przykładów, ale przy trudniejszych zadaniach potrzeba znacznie więcej. Sam trening może trwać od minut do godzin, a przy większych projektach nawet dłużej, zwłaszcza gdy model ma wiele warstw i liczy się na dużych zbiorach. Największa pułapka to przeuczenie: model świetnie zapamiętuje dane treningowe, ale gorzej radzi sobie z nowymi przypadkami. Właśnie dlatego poprawny trening zawsze wymaga także walidacji na danych, których model wcześniej nie widział.
Gdy ten etap jest dobrze ustawiony, model zaczyna być użyteczny w realnych usługach online, a to prowadzi do praktyki, czyli zastosowań w internecie.
Gdzie takie modele pracują w internecie
W produktach internetowych te systemy są często niewidoczne dla użytkownika, ale wpływają na każdy klik. To nie jest ozdobnik technologiczny, tylko warstwa, która pomaga ocenić intencję, kontekst i prawdopodobieństwo zachowania użytkownika.
| Obszar | Co analizuje model | Po co to robi |
|---|---|---|
| Wyszukiwarki | Zapytanie, kontekst, intencję | Lepiej dopasować wyniki do potrzeby użytkownika |
| Rekomendacje | Historię kliknięć, podobne treści, wzorce zachowań | Podsunąć artykuł, produkt lub film, który ma sens w danym momencie |
| Antyspam i antyfraud | Treść wiadomości, metadane i schematy aktywności | Wykryć nadużycie szybciej niż ręczne reguły |
| Moderacja treści | Obrazy, wideo i tekst | Odciąć materiały niebezpieczne lub niepożądane |
| Obsługa głosu i czatu | Transkrypcję, sens wypowiedzi i kontekst rozmowy | Automatyzować kontakt z użytkownikiem |
| Analiza ruchu sieciowego | Wzorce pakietów, anomalie i opóźnienia | Wcześnie wykryć awarię albo atak |
Coraz częściej część obliczeń odbywa się lokalnie w przeglądarce lub na urządzeniu, bo skraca to opóźnienie i ogranicza wysyłanie danych na serwer. To ważne zwłaszcza tam, gdzie liczy się czas reakcji albo prywatność. Kiedy już widać, gdzie model pracuje, warto spojrzeć na jego odmiany, bo nie każdy typ nadaje się do tego samego zadania.
Jakie rodzaje spotkasz najczęściej
Wybór nie sprowadza się do tego, który model jest „nowszy”. Każda architektura ma swój naturalny teren i własne ograniczenia, więc dobieram ją do danych, a nie do mody.
| Architektura | Najlepsza do | Mocna strona | Słabość |
|---|---|---|---|
| MLP, czyli model feedforward | Dane tabelaryczne i prostsza klasyfikacja | Prostota, szybkość, łatwe wdrożenie | Gorzej radzi sobie z obrazem, tekstem i sekwencjami |
| CNN | Obrazy, skany, cechy przestrzenne | Świetnie wykrywa lokalne wzorce | Mniej naturalny poza wizją komputerową |
| RNN, LSTM, GRU | Sekwencje i szeregi czasowe | Uwzględnia kontekst po kolei | Trudniejsze trenowanie i słabsza skalowalność w długich zależnościach |
| Transformer | Tekst, kod i dane multimodalne | Dobrze łapie długie zależności i skaluje się na duże zbiory | Wysoki koszt obliczeń i pamięci |
W praktyce najważniejsze jest nie to, czy model brzmi imponująco, ale czy pasuje do danych i budżetu obliczeniowego. Do prostych prognoz na danych tabelarycznych często wystarczy mniejszy model, a do języka i bardziej złożonych interakcji lepiej sprawdzają się architektury, które potrafią trzymać szerszy kontekst. Z tego wynika ostatnia rzecz, o której wiele projektów przekonuje się dopiero po wdrożeniu: nie każde zadanie w ogóle potrzebuje ciężkiego modelu.
Kiedy prostsze rozwiązanie wygrywa z modelem neuronowym
Jeśli dane są małe, reguły biznesowe jasne, a interpretacja wyniku ważniejsza niż maksymalna skuteczność, prostsze metody często wygrywają. Ja zaczynam od baseline’u, bo to najszybszy sposób, żeby sprawdzić, czy złożony model naprawdę daje przewagę, czy tylko zwiększa koszt.
- Gdy masz mało danych, prostszy model bywa stabilniejszy niż rozbudowana sieć.
- Gdy potrzebujesz pełnej wyjaśnialności, reguły lub modele liniowe są zwykle łatwiejsze do obrony.
- Gdy liczy się czas odpowiedzi, lżejsze rozwiązanie może działać szybciej i taniej.
- Gdy problem da się opisać kilkoma logicznymi regułami, nadmiar złożoności tylko przeszkadza.
- Gdy dane mocno się zmieniają, prosta baza testowa pozwala szybciej wykryć drift niż ciężki model uczony raz na długo.
Najuczciwsza zasada, jaką mogę tu zostawić, jest prosta: wybieraj model najprostszy z tych, które spełniają wymagania. Wtedy łatwiej kontrolować koszty, jakość i ryzyko błędu, a sama architektura pracuje na wynik, zamiast dokładania niepotrzebnej złożoności.