
Rozproszona odmowa usługi potrafi zablokować sklep internetowy, panel klienta albo API w sposób, który dla użytkownika wygląda jak zwykła awaria, choć źródło problemu jest zupełnie inne. W praktyce atak ddos nie polega na przełamaniu zabezpieczeń, tylko na zalewaniu infrastruktury ruchem tak długo, aż zasoby przestają obsługiwać normalne żądania. Poniżej wyjaśniam mechanizm tego zjawiska, pokazuję najczęstsze warianty i rozpisuję zabezpieczenia, które realnie mają sens.
Najważniejsze informacje o DDoS w praktyce
- DDoS uderza w dostępność, a nie w poufność danych, więc celem jest unieruchomienie usługi.
- Źródłem ruchu bywa botnet, czyli sieć przejętych urządzeń sterowanych zdalnie.
- Najgroźniejsze są ataki, które nie tylko obciążają łącze, ale też wyczerpują zasoby serwera, firewalla lub bazy danych.
- Skuteczna obrona zwykle wymaga kilku warstw naraz: CDN, WAF, limitów, ochrony upstream i procedury reakcji.
- Największy błąd to liczenie na jedną blokadę IP. Przy ruchu rozproszonym to za mało.
- W czasie incydentu liczy się nie tylko technika, ale też kolejność działań i szybki kontakt z dostawcą łącza lub ochrony.
Czym różni się DDoS od zwykłej awarii
Na pierwszy rzut oka efekt bywa podobny: strona się nie otwiera, API zwraca błędy, a użytkownicy widzą timeouty. Różnica jest jednak fundamentalna. Przy zwykłej awarii winny bywa błąd konfiguracji, przeciążenie po stronie aplikacji albo problem z bazą. Przy rozproszonej odmowie usługi ktoś celowo generuje taki wzorzec ruchu, który ma zdusić dostępność.
| Cecha | Zwykła awaria | DoS | DDoS |
|---|---|---|---|
| Źródło problemu | Błąd techniczny lub przeciążenie | Jedno albo kilka źródeł | Wiele źródeł, często botnet |
| Cel | Brak intencji ataku | Zablokowanie usługi | Zablokowanie usługi na dużą skalę |
| Ślad w logach | Spójny z ruchem biznesowym | Widoczny, ale ograniczony | Chaotyczny, rozproszony geograficznie |
| Obrona | Naprawa przyczyny | Filtrowanie i blokady | Filtrowanie, ochrona upstream i automatyzacja |
Ja zwykle zaczynam od prostego rozróżnienia: jeśli ruch jest nienaturalny, powtarzalny i nie prowadzi do normalnych zachowań użytkowników, trzeba myśleć o ataku, a nie tylko o skoku popularności. To ważne, bo zła diagnoza opóźnia reakcję i często pogarsza skutki. Właśnie dlatego warto rozumieć, jak taki ruch jest generowany i gdzie najczęściej uderza.
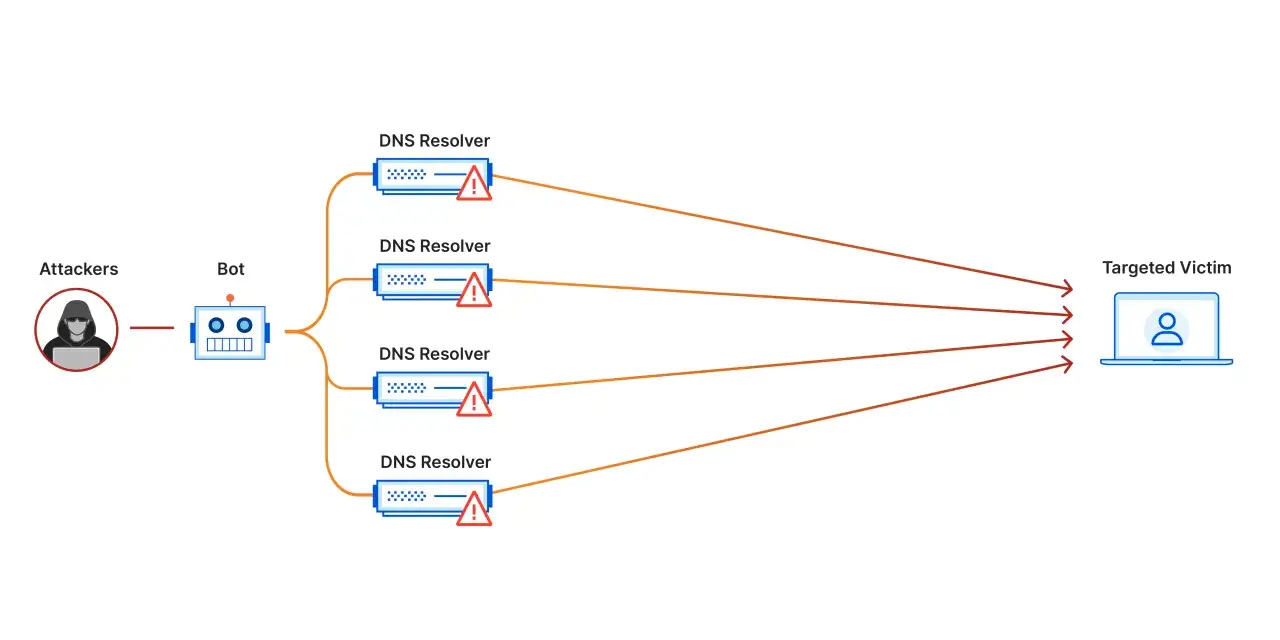
Jak przebiega rozproszony atak w sieci
Mechanizm jest prostszy, niż się wydaje. Atakujący nie musi logować się do serwera ani znać hasła administratora. Wystarczy mu infrastruktura zdolna wygenerować ogromną liczbę żądań, najlepiej z wielu punktów naraz, tak aby ruch wyglądał jak napływ od wielu użytkowników.
Botnet jako źródło mocy
Botnet to sieć urządzeń przejętych przez atakującego, najczęściej komputerów, routerów, kamer IP albo serwerów źle zabezpieczonych przez właścicieli. Każde z nich wysyła tylko niewielką część ruchu, ale razem tworzą strumień, który potrafi przekroczyć przepustowość łącza albo obciążyć aplikację do granic możliwości.
Refleksja i amplifikacja
Jednym z bardziej podstępnych wariantów jest amplification attack, czyli atak wzmacniany przez serwery pośredniczące. Atakujący wysyła małe żądanie do usług trzecich i podaje w nim fałszywy adres ofiary. Odpowiedź wraca już do celu i bywa wielokrotnie większa niż oryginalne zapytanie. Taki mechanizm potrafi zwiększyć siłę ataku bez proporcjonalnego zużycia zasobów po stronie napastnika.
Przeczytaj również: Jak skopiować brelok do domofonu - uniknij problemów z dostępem
Warstwa sieci, transportu i aplikacji
W praktyce ruch może uderzać na różnych poziomach. Atak na warstwie sieciowej zalewa łącze. Atak na warstwie transportowej obciąża mechanizmy zestawiania połączeń. Atak aplikacyjny wygląda bardziej „normalnie”, bo korzysta z HTTP, logowania, wyszukiwania lub koszyka, ale robi to w skali, której aplikacja nie wytrzymuje. I właśnie tu robi się niebezpiecznie, bo sam wolumen nie zawsze zdradza prawdziwy problem.
Jakie warianty spotyka się najczęściej
Nie każdy DDoS działa tak samo. Jeśli chcesz dobrze dobrać ochronę, musisz wiedzieć, co dokładnie jest celem przeciążenia. Inaczej zabezpiecza się łącze, inaczej firewalla, a jeszcze inaczej kosztowny endpoint w aplikacji.
| Typ ataku | Co przeciąża | Typowy objaw | Co pomaga na start |
|---|---|---|---|
| Volumetric | Łącze i przepływność | Serwis „znika” z internetu, rosną timeouty | Ochrona upstream, scrubbing center, CDN |
| Protocol | Stany połączeń, firewalle, load balancery | Urządzenia sieciowe się dławią mimo umiarkowanego ruchu | Filtry na brzegu sieci, tuning limitów sesji |
| Application layer | CPU, bazę danych, cache, endpointy logowania lub wyszukiwania | Strona działa wolno, ale tylko wybrane funkcje padają | WAF, rate limiting, cache, ochrona kosztownych zapytań |
Najgroźniejsze są ataki warstwy aplikacji, bo potrafią wyglądać jak „prawdziwi” użytkownicy. W praktyce jedno kosztowne zapytanie do bazy potrafi być bardziej dotkliwe niż setki prostych odświeżeń strony głównej. Dlatego sama przepustowość nie wystarcza jako miara bezpieczeństwa. Trzeba jeszcze rozumieć, jak rozpoznać, że ruch przestał być naturalny.
Po czym odróżnić atak od naturalnego skoku ruchu
Ja zaczynam od pytania, czy biznesowy ruch ma sens. Jeśli serwis właśnie wystartował po kampanii, pojawił się w mediach albo wszedł na niego ruch po newsletterze, skok odwiedzin może być całkiem normalny. Jeśli jednak wzrost jest nagły, chaotyczny i nie przekłada się na realne sesje lub konwersje, zapala się czerwona lampka.
| Wskaźnik | DDoS | Naturalny wzrost ruchu |
|---|---|---|
| Start | Nagły, bez biznesowego powodu | Związany z wydarzeniem, kampanią lub publikacją |
| Wzorzec żądań | Powtarzalny, często do jednego endpointu | Różnorodny, zgodny z zachowaniem użytkowników |
| Źródła | Wiele IP, nietypowe regiony, podejrzane ASN | Znane kraje i kanały sprzedażowe |
| Efekt biznesowy | Wzrost błędów i timeoutów, brak konwersji | Więcej wejść, ale też więcej zakupów, leadów lub rejestracji |
- Rośnie liczba 502, 503 lub 504, a użytkownicy zgłaszają timeouty.
- W logach widać lawinę podobnych żądań do jednego endpointu, na przykład logowania, wyszukiwania albo koszyka.
- Firewall, load balancer lub reverse proxy zaczynają pracować gorzej niż sam serwer aplikacji.
- Ruch przychodzi z wielu adresów, ale zachowuje się zaskakująco podobnie.
- Kosztowne zapytania do bazy albo zewnętrznych API uruchamiają się częściej niż zwykle.
W praktyce nie chodzi o jeden magiczny wskaźnik. Liczy się zestaw objawów. Gdy widzę jednocześnie skok błędów, nietypowe źródła i powtarzalne zachowanie, traktuję to jako problem bezpieczeństwa, a nie zwykłą awarię. Z tej diagnozy wynika dalszy krok, czyli obrona warstwowa.
Jak bronić serwisu warstwowo
Ja zwykle układam obronę warstwowo, bo pojedynczy filtr nie obroni wszystkiego. Celem nie jest tylko zatrzymanie ruchu, ale też utrzymanie dostępności dla uczciwych użytkowników i zachowanie kontroli nad kosztami. W praktyce najlepiej działają zabezpieczenia rozłożone od brzegu sieci aż po samą aplikację.
| Warstwa | Co wdrożyć | Po co to robić | Ograniczenie |
|---|---|---|---|
| Brzeg sieci | Ochronę upstream, scrubbing center, anycast | Odfiltrowuje duży wolumen zanim dotrze do infrastruktury | Wymaga dobrego dostawcy i konfiguracji przed atakiem |
| Warstwa HTTP | CDN, WAF, cache, bot management | Zmniejsza liczbę żądań trafiających do origin | Nie zatrzyma wszystkiego, zwłaszcza ataków bardzo „ludzkich” |
| Aplikacja | Rate limiting, circuit breaker, limity na kosztowne endpointy | Chroni logowanie, wyszukiwanie, koszyk i API | Źle ustawione limity mogą uderzyć w prawdziwych użytkowników |
| Operacje | Monitoring, alerty, runbook, kontakt do ISP | Skraca czas reakcji i zmniejsza chaos | Bez ćwiczeń procedury zwykle zostają na papierze |
Warto też pamiętać o kompromisie między modelem always-on a on-demand. Jak wskazują CISA, FBI i MS-ISAC, rozproszony atak zwykle pochodzi z wielu źródeł, więc blokowanie pojedynczych IP jest spóźnione. Ochrona działająca stale reaguje szybciej, ale potrafi kosztować więcej i dodać trochę opóźnienia. Tryb uruchamiany dopiero w kryzysie bywa tańszy, ale jeśli procedura jest słaba, cenny czas ucieka właśnie wtedy, gdy jest najbardziej potrzebny.
Co zrobić, gdy ruch już zalewa system
W incydencie najgorsze są improwizacja i nerwowe klikanie. W pierwszej kolejności trzeba ustalić, czy problem dotyczy łącza, aplikacji czy konkretnego endpointu. Dopiero potem ma sens ręczne blokowanie, przepinanie ruchu albo uruchamianie planu awaryjnego.
- Potwierdź, że to nie awaria lokalna. Sprawdź monitoring, logi, stan DNS i odpowiedzi z kilku lokalizacji.
- Włącz lub podbij ochronę u dostawcy, CDN albo operatora łącza, zamiast próbować dusić ruch wyłącznie po swojej stronie.
- Zachowaj logi i zrzuty metryk. Po incydencie to one pokażą, co było celem i jak atak się zmieniał.
- Odciąż aplikację, wyłącz kosztowne funkcje, ogranicz limity na logowanie, wyszukiwanie i inne ciężkie endpointy.
- Poinformuj zespół i użytkowników o czasie niedostępności, jeśli już wiesz, że nie jest to kilka minut pracy.
- Po ustabilizowaniu ruchu przejrzyj ustawienia i sprawdź, co zawiodło w procedurze, a nie tylko w technologii.
Według CERT Polska zgłoszenia takich incydentów mają sens zwłaszcza wtedy, gdy atak dotyka usług w Polsce albo sprawy wymagają wsparcia analitycznego. W praktyce dobrze jest dołączyć logi, godzinę początku, opis objawów i informację, jakie zabezpieczenia zostały już włączone. To skraca diagnostykę i pozwala szybciej odróżnić przypadkowy skok ruchu od zorganizowanego ataku.
Jak przygotować serwis, zanim botnet sprawdzi jego granice
Najlepsza ochrona przed DDoS zaczyna się zanim pojawi się pierwszy incydent. Ja patrzę na to jak na ubezpieczenie infrastruktury: nie kupuje się go po pożarze, tylko wcześniej. W cyberbezpieczeństwie dokładnie tak samo działa plan reakcji, bo wtedy zespół nie musi wymyślać procedury w środku kryzysu.
- Spisz runbook, czyli prostą instrukcję reakcji krok po kroku dla dyżurnego i administratora.
- Ustal kontakty do ISP, operatora chmury, dostawcy CDN i osoby decyzyjnej po stronie biznesu.
- Oznacz endpointy, które są drogie obliczeniowo, i ogranicz ich ekspozycję, zanim ktoś zacznie je testować ruchem.
- Przetestuj limity, cache i tryb awaryjny na kontrolowanym ruchu, a nie w czasie prawdziwego incydentu.
- Rozdziel panel administracyjny od publicznej części serwisu i nie wystawiaj go bez sensu do internetu.
- Utrzymuj sensowne alerty, żeby odróżnić skok legalnego ruchu od wzorca typowego dla botów.
Największy błąd, jaki obserwuję, to wiara, że „jakoś to będzie”, bo serwis jeszcze nigdy nie padł. Taka pewność kończy się zwykle pierwszym większym ruchem z zewnątrz. Jeśli chcesz naprawdę ograniczyć ryzyko, postaw na ochronę wielowarstwową, dobrą telemetrię i jasny plan reakcji. To właśnie te elementy najczęściej decydują o tym, czy incydent trwa kilka minut, czy zamienia się w kosztowny przestój.